🟦Стратификация#
Существует замечательная статья на эту тему.
Необходимо оценить популяционное среднее метрики \(Y\).
Обозначение:
\(\mu = EY\) - популяционное среднее
\(\sigma^2\) - популяционная дисперсия
\(\mu_k, \sigma^2_k\) - среднее и дисперсия метрикик для \(k\)-ой страты
\(n_k\) - число пользователей из \(k\)-ой страты
\(n = \sum_{k=1}^K n_k\) - общий размер группы
\(w_k\) - доля \(k\)-ой страты в популяции
\(Y_{1, 1}, Y_{1, 2}, ..., Y_{1, n_1}, ..., Y_{k, 1}, ..., Y_{k, n_k}\) - выборка из генеральной совокупности, где \(Y_{k, j}\) - метрика \(j\)-го пользователя \(k\)-ой страты.
Точечные оценки: Для популяционного среднего можно рассмотреть две несмещенные точечные оценки.
\(\overline Y = \frac{1}{n}\sum_{k=1}^K \sum_{j=1}^{n_k} Y_{k, j}\)
\(\hat{Y}_{strat} = \sum_{k=1}^K w_k \overline{Y}_k \,\,\,\,\,\overline{Y}_k= \frac{1}{n_k} \sum_{j=1}^{n_k} Y_{k, j}\)
Основная идея метода
Стратифицированная семплирование - метод понижения дисперсии. Для выборки мы должны обеспечить такие же доли каждой страты, что и в генеральной совокупности(на исторических данных). Размеры страт \(n_k = nw_k\).
Способы семплирования:
Случайное семплирование Мы выбираем элементы без дополнительных требований по доле каждой из страт. \((E_{srs}, D_{srs})\).
Cтратифицированное семплирование Частоты каждой страты должны быть такой же как и в ГС \((E_{strat}, D_{strat})\).
Совпадение точечных оценок В условиях стратифицированного семплирования две привденные точечные оценки совпадают:
Стратифицированное среднее и простое среднее являются несмещенными оценками:
Закон полного математического ожидания
Закон полной дисперсии
где \(E[D[X|Y]]\) - средняя дисперсия по группам, \(D[E[X|Y]]\) - вариация среднего по группам.
Дисперсия случайного семплирования может быть предствлена в виде суммы дисперсии внутри стратифицированной группы и между стратифицированными группами.
Выше дисперсия одной случайной величины, полученной с помощью случайного семлирования.
Посчитаем диспресию случайного семплирования:
Дисперсия стратифицированного семплирования выводится примерно также:
Таким образом, с помощью стратификации получится понизить дисперсию на
Чем сильнее различия между средними в стратах, тем сильнее будет снижение дисперсии.
Постстратификация#
Мы можем заменить случайное среднее на стратифицированное срендее
Это соотвествует перевзвешиванию каждой страты в соответствии с долей в Г.С. (\(w_k\) получаем по историческим данным).
Оценим дисперсию стратифицированного среднего при случайном семплировании.
\(n_k\) - биномиальное распределение (сумма Бернулли).
Дисперсия биномиальной случайной величины:
Применим разложение Тейлора для функции \( \frac{1}{n_k} \) в точке \( \frac{1}{n w_k} \):
Так как
то:
Подставив в (*), получаем:
Сравнение различных методов:
\( D_{srs}[\overline Y] = \frac{1}{n^2} n \sigma^2 = \frac{1}{n} \sum_{k=1}^K w_k \sigma^2_k + \frac{1}{n}\sum_{k=1}^K w_k(\mu_k - \mu)^2 \)
\( D_{strat}[\hat Y_{strat}] = \frac{1}{n} \sum_{k=1}^K w_k \sigma^2_k \)
\( D_{srs}[\hat{Y}_{strat}] =\frac{1}{n} \sum_{k=1}^K w_k \sigma_k^2 +\frac{1}{n^2} \sum_{k=1}^K (1 - w_k) \sigma_k^2 +O\left(\frac{1}{n^2}\right) \)
\( D_{strat}[\hat Y_{strat}] \leq D_{srs}[\hat{Y}_{strat}] \leq D_{srs}[\overline Y] \)
Код
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy import stats
N = 1000
n_iter = 10000
data = np.zeros(2 * N)
data[:N] = 1
res = []
sample_sizes = [10, 20, 50, 100, 500]
for sample_size in sample_sizes:
list_part_second_strata = []
for _ in range(n_iter):
sample = np.random.choice(data, sample_size, False)
list_part_second_strata.append(np.mean(sample))
res.append(list_part_second_strata)
df_res = pd.DataFrame(res, index=sample_sizes).T
fig = plt.figure(figsize=[12, 8])
sns.violinplot(data=df_res, cut=1, linewidth=1)
plt.title('Распределение доли одной из страт в зависимости от размера выборки')
plt.grid()
plt.show()
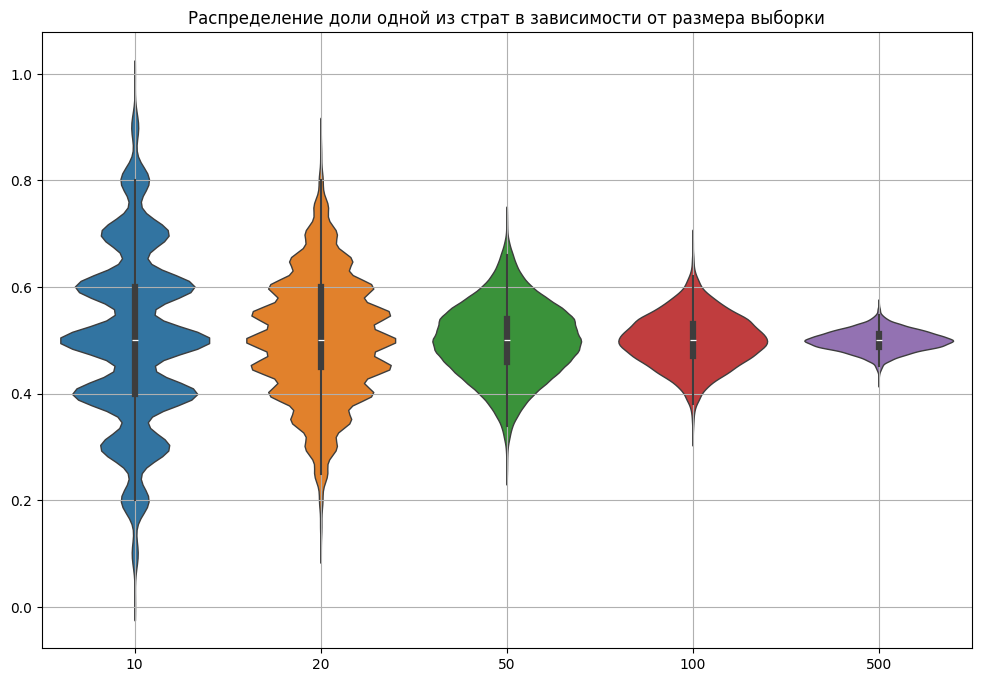
Маленькие выборки несут заметный риск нерепрезентативности.
Иногда можно такую ситуацию предотвратить на этапе дизайна эксперимента. И заранее предусмотреть выбор репрезентативных групп. Но это возможно далеко не всегда. Так если значимых признаков много, то группы получаются сравнительно малого размера и точно подобрать репрезентативные выборки как минимум тяжело. По тем или иным признакам мы можем получить отклонения.
Кроме того, для малых групп существует дополнительная проблема: несбалансированность представленности признака в пилотной и контрольной группах.
Если мы случайным образом распределяем пользователей в пилотную и контрольную группы, то при условии того, что всего будет выбрано \(N\) пользователей обладающих определенным признаком, число таких пользователей в пилотной группе будет подчиняться биномиальному распределению.
Можно посчитать вероятность значительных перекосов: отличия в пилотной и контрольной группах более чем в \(K\) раз. Для этого воспользуемся функцией scipy.stats.binom:
scipy.stats.binom(*args, **kwds)
N = np.arange(10, 1000)
plt.title('Вероятность перекосов')
for K in [1.25, 1.5, 2, 3]:
prob = 2 * stats.binom.cdf(N / (1 + K), N, 0.5)
plt.plot(N, prob, label=f'K = {K}')
plt.xscale('log')
plt.legend()
plt.grid()
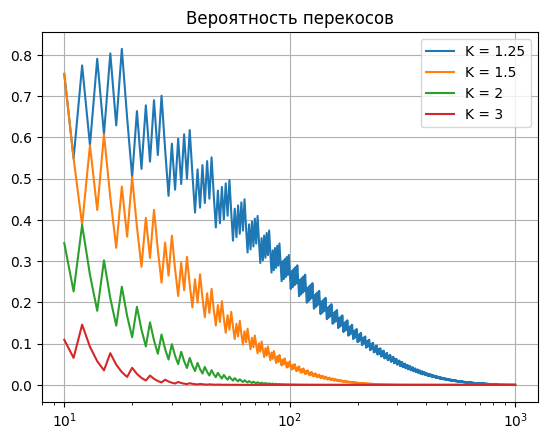
При увеличении размера выборки вероятность того, что выборка будет несбалансированная уменьшается.
Однако можно видеть, что даже при размере группы \(N=100\) вероятность получить пилотную и контрольную группы отличающимися более чем на 25% составляет \(p=0.3\). С учетом того, что значимых признаков может быть много, мы действительно часто вынуждены работать с малыми группами. Поэтому надо разобраться как такие перекосы влияют. И как можно ситуацию улучшить.
2. Дисперсия при стратификации#
Сравним как меняется дисперсия при стратификации и случайном сэмплировании для различных исходных данных.
Мы можем рассмотреть три подхода к семплированию:
Случайное семплирование. Из всего датасета (объединения данных по отдельным стратам) мы берем без возвращений случайный семпл заданного размера. Для такой выборки считаем среднее.
Стратифицированное семплирование. Из каждой страты мы выбираем число объектов пропорциональное размеру этой страты в генеральной совокупности. Объединяем полученные выборки в итоговую и для неё считаем среднее.
Постстратификация. Если выборка уже сформирована, то считаем среднее для каждой отдельной страты и берем их взвешенную сумму с весами страт из генеральной совокупности.
Для каждого из трех случаев оценим дисперсию полученной случайной величины.
def get_sample_mean(data, size):
return np.random.choice(data, size, False).mean()
def calc_srs_stats(
strata: list,
sample_size=100, n_iter=1000
):
"""Считаем дисперсию обычного среднего при случайном сэмплировании.
strata - список страт
sample_size - размер сэмплируемой выборки
n_iter - кол-во итераций сэмплирования
return: среднее средних, дисперсия средних
"""
data = np.concatenate(strata)
means = [get_sample_mean(data, sample_size) for _ in range(n_iter)]
return np.mean(means), np.var(means)
def calc_strat_stats(
strata: list,
sample_size=100, n_iter=1000,
is_stratified=True
):
"""Считаем дисперсию среднего значения при стратифицированном сэмплировании.
strata - список страт
sample_size - размер сэмплируемой выборки
n_iter - кол-во итераций сэмплирования
is_stritified - флаг стратификационного семплирования (сохраняем ли мы пропорции страт)
return: среднее средних, дисперсия средних
"""
strata_sizes = [len(stratum) for stratum in strata]
full_size = np.sum(strata_sizes)
weights = np.array(strata_sizes) / full_size
sample_sizes = np.zeros(shape=len(strata))
if is_stratified:
sample_sizes = (weights * sample_size + 0.5).astype(int)
else:
while (np.array(sample_sizes)).min() == 0:
sample_sizes = np.random.default_rng().multinomial(sample_size, weights)
assert sample_sizes.min() != 0
means = []
for _ in range(n_iter):
strata_means = [get_sample_mean(stratum, size) for stratum, size in zip(strata, sample_sizes)]
means.append((weights * np.array(strata_means)).sum())
return np.mean(means), np.var(means)
def calc_srs_strat_stats(
strata: list,
sample_size=100, n_iter=1000
):
"""Считаем дисперсию среднего стратифицированного при случайном сэмплировании.
strata - список страт
strata_second - множества значений второй страты
sample_size - размер сэмплируемой выборки
n_iter - кол-во итераций сэмплирования
return: среднее средних, дисперсия средних
"""
return calc_strat_stats(strata, sample_size=sample_size, n_iter=n_iter, is_stratified=False)
Напишем функцию для проведения экспериментов.
Эта функция будет последовательно вызывать все виды подсчета среднего и выводить статистику.
def run_calc_vars(
strata: list,
sample_size=100, n_iter=1000,
show=False
):
"""Cчитает средние и дисперсии средних значений, посчитанных при
сэмплировании разными способами.
"""
function_dict = {
'strat': calc_strat_stats,
'srs_strat': calc_srs_strat_stats,
'srs': calc_srs_stats
}
res_dict = {}
for function_name, function in function_dict.items():
mean_, var_ = function(strata, sample_size, n_iter)
res_dict[f'mean {function_name}'] = mean_
res_dict[f'var {function_name}'] = var_
if show:
print(f'{function_name:<10} mean {mean_:0.4f}, var {var_:0.4f}')
return res_dict
Проведем серию численных экспериментов#
При одинаковых распределениях в стратах дисперсии должны быть одинаковы. Разница средних же обеспечивает различие в дисперсиях.
np.random.seed(45)
data_for_experiments = [
{
'experiment_title': 'Same mean, same variance',
'strata': [
np.random.normal(0, 1, 100),
np.random.normal(0, 1, 100),
]
},
{
'experiment_title': 'Same mean, different variance',
'strata': [
np.random.normal(0, 1, 100),
np.random.normal(0, 2, 100),
]
},
{
'experiment_title': 'Different mean, same variance',
'strata': [
np.random.normal(0, 1, 100),
np.random.normal(2, 1, 100),
]
},
{
'experiment_title': 'Different mean, different variance',
'strata': [
np.random.normal(0, 1, 100),
np.random.normal(40, 2, 100),
]
},
]
sample_size = 100
n_iter = 10000
for data in data_for_experiments:
print(f'\n Experiment: {data["experiment_title"]}')
_ = run_calc_vars(data['strata'], sample_size, n_iter, show=True)
Experiment: Same mean, same variance
strat mean -0.0316, var 0.0046
srs_strat mean -0.0323, var 0.0048
srs mean -0.0309, var 0.0048
Experiment: Same mean, different variance
strat mean -0.0575, var 0.0117
srs_strat mean -0.0559, var 0.0116
srs mean -0.0570, var 0.0123
Experiment: Different mean, same variance
strat mean 0.9366, var 0.0046
srs_strat mean 0.9375, var 0.0049
srs mean 0.9364, var 0.0103
Experiment: Different mean, different variance
strat mean 19.9789, var 0.0139
srs_strat mean 19.9783, var 0.0128
srs mean 19.9867, var 2.0294
Как и ожидалось, различия в дисперсии у нас определяются разницей в средних значениях между стратами.
Построим зависимость дисперсии оценок среднего в зависимости от размера выборки#
def plot_mean_var(df):
"""Рисует графики средних и дисперсий по значениям в столбцах датафрейма."""
columns = df.columns
columns_var = [c for c in columns if 'var' in c]
columns_mean = [c for c in columns if 'mean' in c]
fig = plt.figure(figsize=[16, 6])
ax_one = plt.subplot(121)
df[columns_var].plot(ax=ax_one)
ax_one.set_title('var')
plt.grid()
ax_two = plt.subplot(122)
df[columns_mean].plot(ax=ax_two)
ax_two.set_title('mean')
ax_two.set_ylim([-0.1, df[columns_mean].values.max() * 1.1])
plt.grid()
np.random.seed(45)
data_first = np.random.normal(0, 1, 100)
data_second = np.random.normal(2, 1, 100)
sample_sizes = np.arange(5, 100, 5)
n_iter = 10000
res = []
for sample_size in sample_sizes:
res.append(run_calc_vars([data_first, data_second], sample_size, n_iter, show=False))
df = pd.DataFrame(res, index=sample_sizes)
plot_mean_var(df)
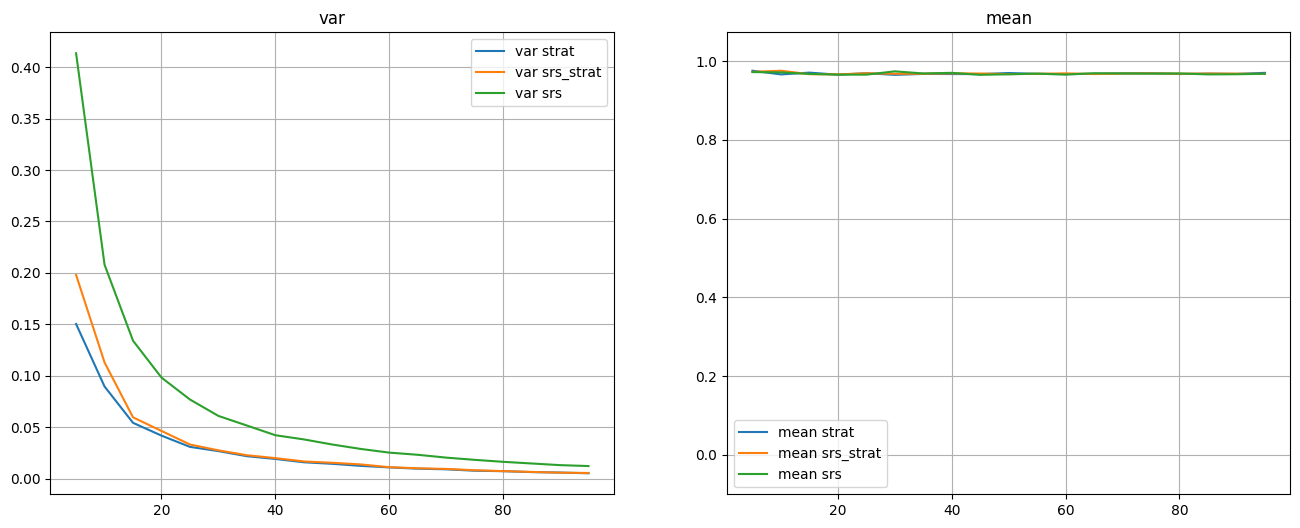
Численные эксперимент согласуется с теорией. Дисперсия располагаются так $\(var_{srs} \geq var_{srs\_strat} \geq var_{strat}\)$
При увеличении размера выборки \(var_{srs\_strat} \approx var_{strat}\).
Построим зависимость дисперсий от величины отличия средних между стратами#
np.random.seed(45)
sample_size = 40
n_iter = 1000
mean_deltas = np.linspace(0, 5, 51)
data_first = np.random.normal(0, 1, 100)
data_second = np.random.normal(0, 1, 100)
res = []
for mean_delta in mean_deltas:
res.append(run_calc_vars([data_first, data_second + mean_delta], sample_size, n_iter, show=False))
df = pd.DataFrame(res, index=mean_deltas)
plot_mean_var(df)
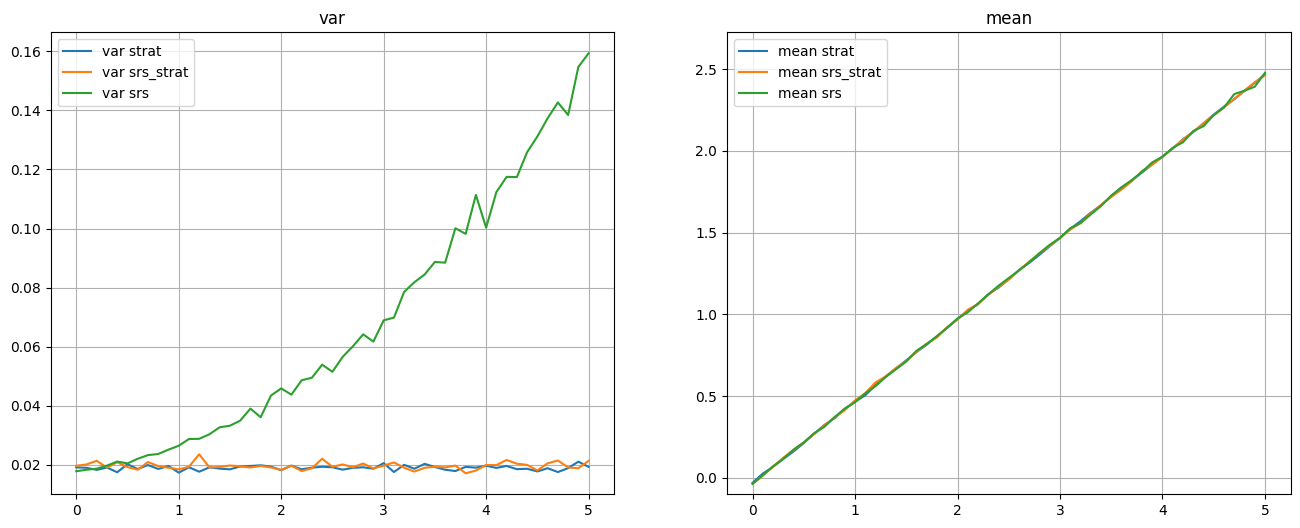
При увеличении отличий между стратами дисперсии strat и srs_strat практически не изменяются, а дисперсия srs растёт.
Давайте оценим ошибки 1 и 2 рода#
def get_confidence_interval(mu, se):
quant = stats.norm.ppf(0.975)
return mu - quant * se, mu + quant * se
def dot_in_interval(lb, rb, dot=0):
return lb <= dot <= rb
size = 1000
std = 100
mu = 100
weight = 0.5 # size are equal
first_type_errors_srs = []
first_type_errors_strat = []
for _ in range(10**4):
strata_first = np.random.normal(-mu, std, size)
strata_second = np.random.normal(mu, std, size)
all_data = np.concatenate((strata_first, strata_second))
mean = np.mean(all_data)
var_srs = np.var(all_data) / len(all_data)
std_srs = var_srs ** 0.5
var_strat = (
weight * np.var(strata_first) +
(1 - weight) * np.var(strata_second)
) / len(all_data)
std_strat = var_strat ** 0.5
ci_srs = get_confidence_interval(mean, std_srs)
ci_strat = get_confidence_interval(mean, std_strat)
first_type_errors_srs.append(~dot_in_interval(*ci_srs, 0))
first_type_errors_strat.append(~dot_in_interval(*ci_strat, 0))
print(np.mean(first_type_errors_srs))
print(np.mean(first_type_errors_strat))
0.0038
0.0469