🟦Разложение ошибки на смещение и разброс#
Случайности:
\(X = (x, y)_{i=1}^n\) - обучающая выборка
\(\varepsilon\) - шум
Рассмотрим задачу регрессии с квадратичной функцией потерь. Представим также для простоты, что целевая переменная \(y\) — одномерная и выражается через переменную \(x\) как:
где \(f\) - некоторая ограниченная функция, а \(\varepsilon\) - случайный шум с слудующими свойствами \(\mathbb{E}\varepsilon = 0\), \(\mathbb{V}\varepsilon = \mathbb{E}\varepsilon^2 = \sigma^2\).
Функция потерь на одном объекте \(x\) равна \(MSE = \left(y(x) - a(x)\right)^2\), причем \(a = a(x, X)\), где \(X\) - выборка, на которой происходило обучение, а \(y = y(x, \varepsilon)\).
Наконец, измерять качество мы бы хотели на тестовых объектах \(x\) — тех, которые не встречались в обучающей выборке, а тестовых объектов у нас в большинстве случаев более одного. При включении всех вышеперечисленных источников случайности в рассмотрение логичной оценкой качества алгоритма \(a\) кажется следующая величина:
Внутреннее матожидание позволяет оценить качество работы алгоритма в одной тестовой точке \(x\) в зависимости от всевозможных реализаций \(X\) и \(\varepsilon\), а внешнее матожидание усредняет это качество по всем тестовым точкам. Т.к. \(X\) и \(\varepsilon\) независимы, то \(\mathbb{E}_{X, \varepsilon} = \mathbb{E}_{X}\mathbb{E}_{\varepsilon}\).
Попробуем представить выражение для \(Q(a)\) в более удобном для анализа виде. Начнём с внутреннего матожидания:
Из общего выражения для \(Q(a)\) выделилась шумовая компонента \(\sigma^2\). Продолжим преобразование:
Таким образом, итоговое выражение для \(Q(a)\) примет вид:
\( Q(a) = \mathbb{E}_x\mathbb{E}_{X, \varepsilon} \left[y(x, \varepsilon) - a(x, X)\right]^2 = \mathbb{E}_x bias^2_X a(x, X) + \mathbb{E}_x\mathbb{V}_X[a(x, X)] + \sigma^2 \),
где
\(bias^2_X a(x, X) = f(x) - \mathbb{E}_{X}[a(x, X)]\) - смещение предсказания алгоритма в т. \(x\), усредненного по всем возможным обучающим выборкам, относительно истинной зависимости \(f\);
\(\mathbb{V}_X[a(x, X)] = \mathbb{E}_{X}[a(x, X) - \mathbb{E}_{X}[a(x, X)]]^2\) - дисперсия (разброс) предсказаний алгоритма в зависимости от обучающей выборки \(X\)
\(\sigma^2 = \mathbb{E}_{x}\mathbb{E}_{\varepsilon}[y(x, \varepsilon)-f(x)]^2\) - неустранимый шум в данных.
Смещение показывает, насколько хорошо с помощью данного алгоритма можно приблизить истинную зависимость \(f\), а разброс характеризует чувствительность алгоритма к изменениям в обучающей выборке. Например, деревья маленькой глубины будут в большинстве случаев иметь высокое смещение и низкий разброс предсказаний, так как они не могут слишком хорошо запомнить обучающую выборку. А глубокие деревья, наоборот, могут безошибочно выучить обучающую выборку и потому будут иметь высокий разброс в зависимости от выборки, однако их предсказания в среднем будут точнее. На рисунке ниже приведены возможные случаи сочетания смещения и разброса для разных моделей:
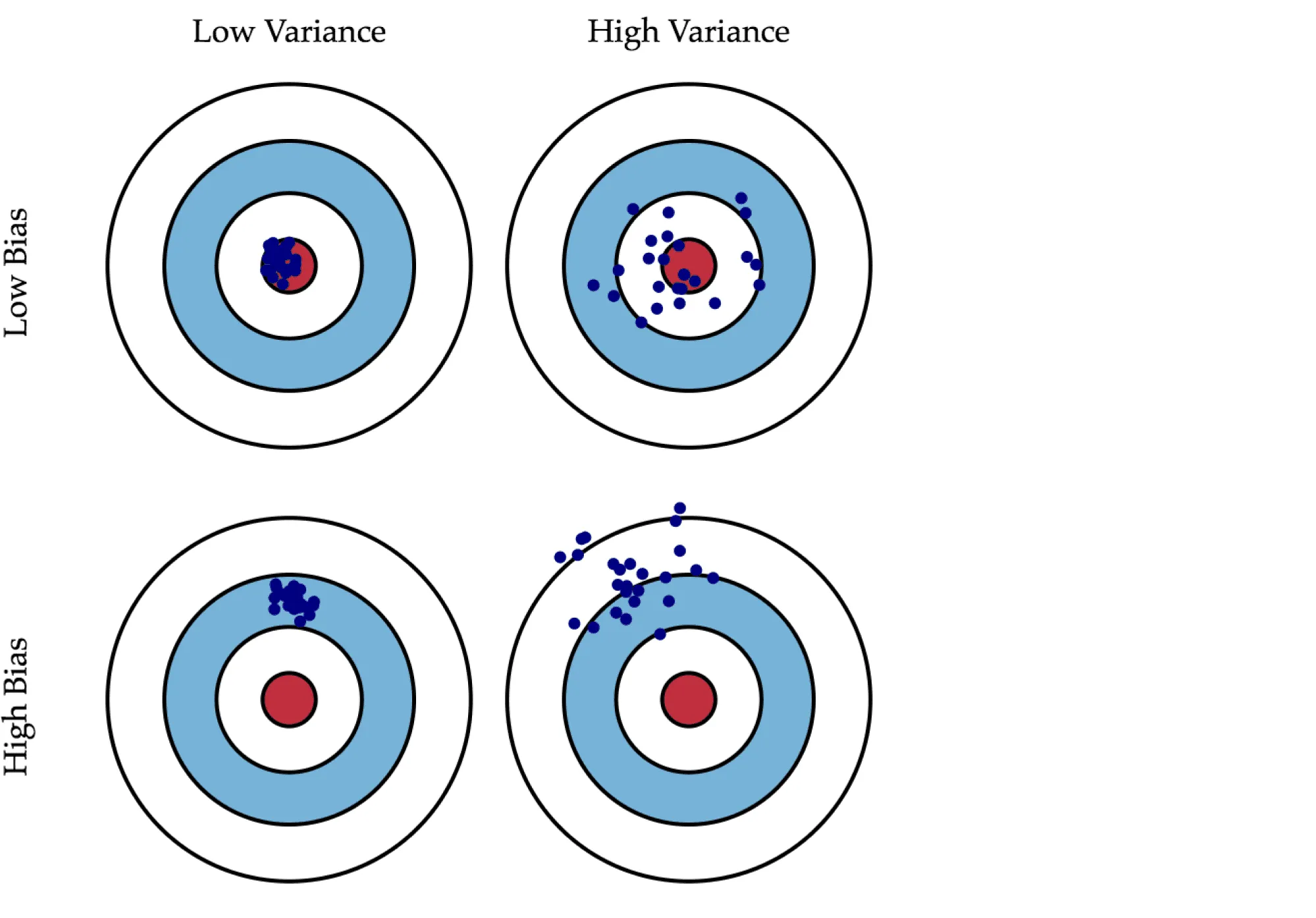
Синяя точка соответствует модели, обученной на некоторой обучающей выборке, а всего синих точек столько, сколько было обучающих выборок. Красный круг в центре области представляет ближайшую окрестность целевого значения. Большое смещение соответствует тому, что модели в среднем не попадают в цель, а при большом разбросе модели могут как делать точные предсказания, так и довольно сильно ошибаться.