🟦 Эмпирическая функция распределения#
Эмпирическая функция распределения (ЭФР) — это функция, построенная на основании выборки
\(X_1, X_2, \ldots, X_n\) и описывающая, какая доля наблюдений не превышает заданное значение \(x\).
где \(I(\cdot)\) — индикаторная функция (равна \(1\), если условие выполняется, и \(0\) иначе).
Интерпретация
ЭФР \(F_n(x)\) является приближением истинной функции распределения \(F(x)\) случайной величины \(X\).
Она показывает долю элементов выборки, значения которых не превышают \(x\).
Свойства
\(F_n(x)\) — неубывающая функция: если \(x_1 < x_2\), то \(F_n(x_1) \le F_n(x_2)\);
\(F_n(x)\) — правосторонне непрерывна;
\(\lim_{x \to -\infty} F_n(x) = 0\) и \(\lim_{x \to +\infty} F_n(x) = 1\);
Для любого \(x\) значение \(F_n(x)\) изменяется только в точках выборки \(X_i\) и
имеет вид ступенчатой функции, увеличиваясь на \(1/n\) в каждой точке \(X_i\);Для любого фиксированного \(x\):
\[ \mathbb{E}[F_n(x)] = F(x), \quad \mathbb{D}[F_n(x)] = \frac{F(x)(1 - F(x))}{n}. \]
🔹Теорема Гливенко — Кантелли#
Теорема Гливенко — Кантелли утверждает, что эмпирическая функция распределения
равномерно сходится к истинной функции распределения с вероятностью 1.
📎 Следствие
Это означает, что при увеличении объёма выборки эмпирическая функция распределения
всё лучше приближает истинную \(F(x)\) — для всех \(x\) одновременно, а не только в отдельных точках.
🟦 Статистические оценки параметров распределения#
Статистическая оценка — это функция от выборки, предназначенная для приближённого нахождения неизвестного параметра или функции от параметра распределения.
Пусть выборка \(X_1, X_2, \ldots, X_n\) получена из генеральной совокупности с распределением, зависящим от параметра \(\theta\).
Тогда оценкой функции параметра \(\tau(\theta)\) называется случайная величина построенная на основе выборочных данных.
Точечная оценка — это статистическая оценка, которая задаёт одно конкретное значение параметра или функции параметра \(\tau(\theta)\), в отличие от интервальной оценки, задающей диапазон значений.
🟦 Статистические свойства оценок#
🔹Несмещенность#
Оценка \(T\) называется несмещённой оценкой функции параметра \(\tau(\theta)\),
если её математическое ожидание совпадает с этой функцией:
Если это равенство не выполняется, то оценка называется смещённой,
а величина
называется смещением оценки.
Несмещенность оценки математического ожидание и смещенность дисперсии
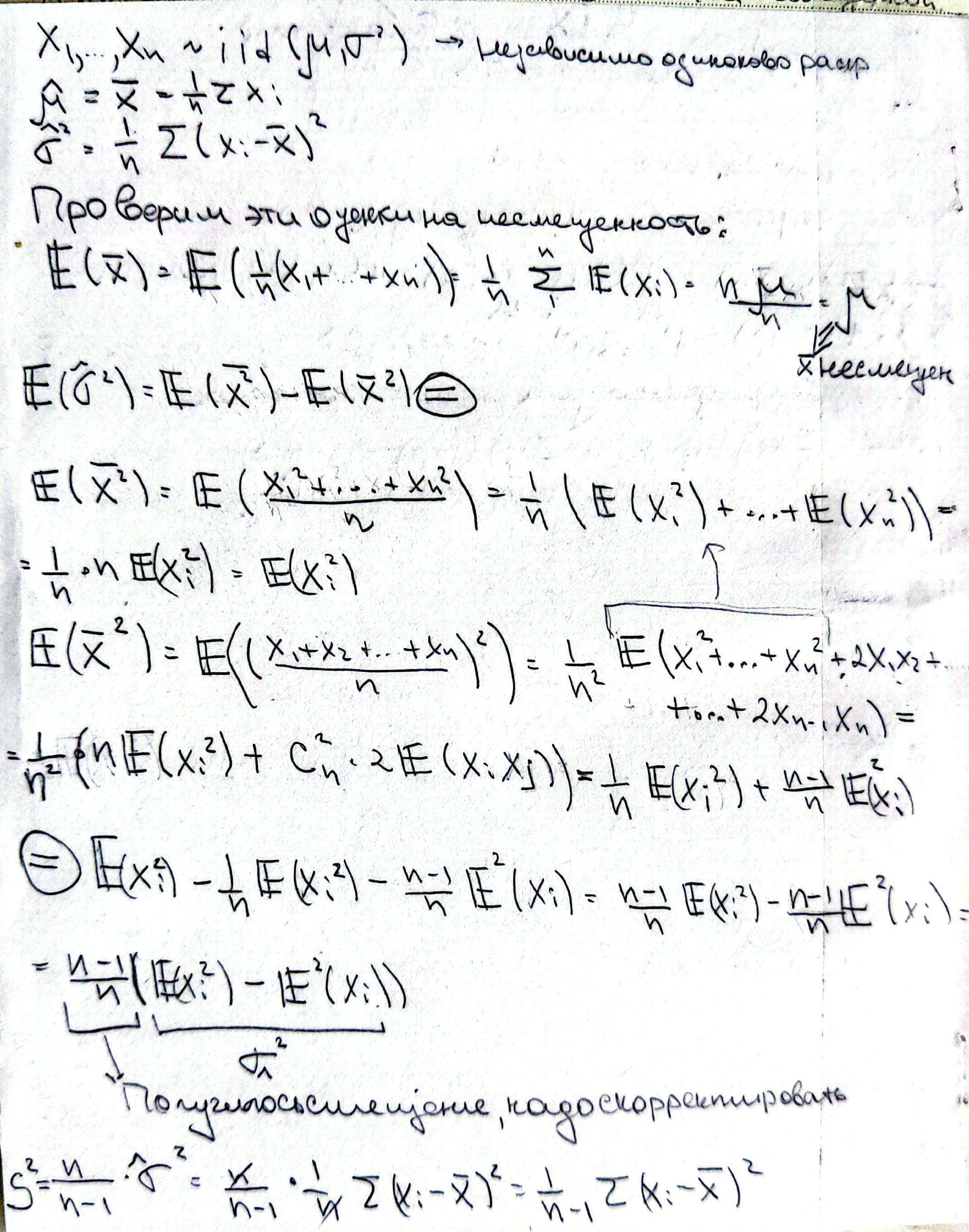
🔹Состоятельность#
Статистика \(T(X)\), где \(X = X_1, X_2, ...,X_n\), называется состоятельной оценкой \(\tau(\theta)\), если
По сути состоятельность ялвяется гарантией того, что при увеличении выборки \(n \rightarrow \infty\) оценка будет приближаться к истинному значению параметра.
Пример:
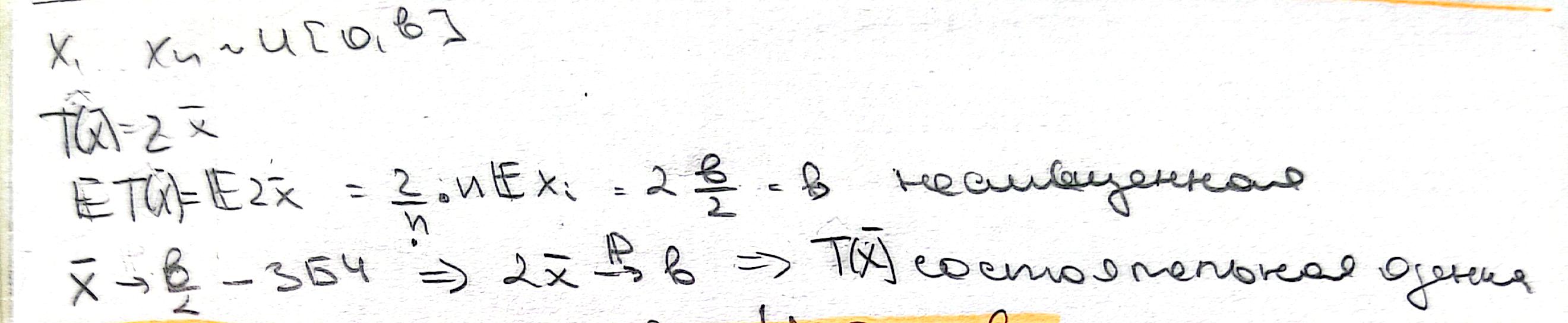
Достаточное условие Чебышева Пусть \(T(X)\) оценка параметра \(\tau(\theta)\). Если она несмещенная и \(Var\left(T(X)\right) \rightarrow 0\) при \(n\rightarrow \infty\), то \(T(X)\) состоятельная оценка для \(\tau(\theta)\).
Пример:
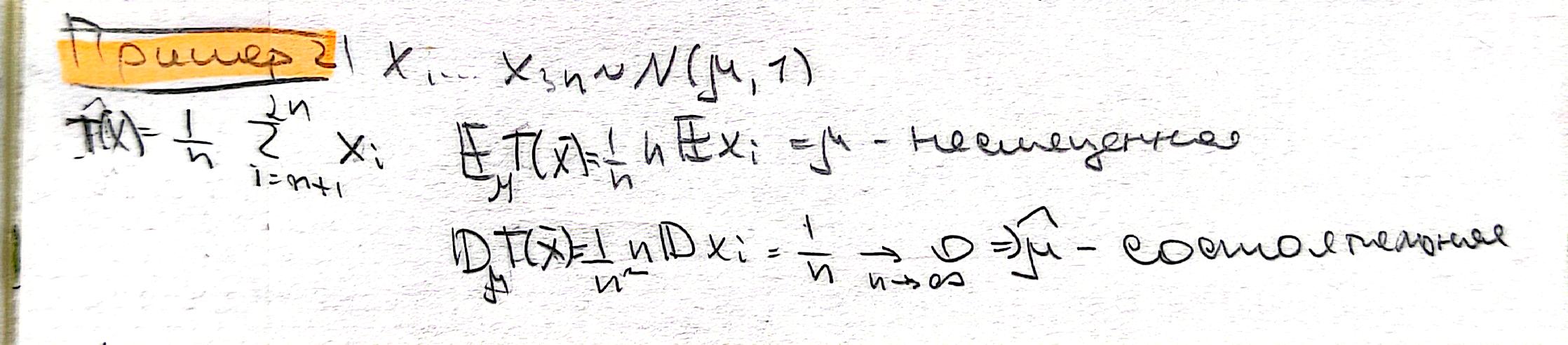
🔹Достаточность#
Статистика \(T(X)\) называется достаточой оценкой \(\tau(\theta)\), если распределение выборки \(X_1, X_2, ..., X_n(\sim F ( \theta))\) при условии \(T(X) = t\) не зависит от \(\theta\).
не зависит от \(\theta\).
Критерий факторизации
Если функция правдоподобия, построенная по \(X = X_1, X_2, ..., X_n\), представима в виде:
то \(T(X)\) - достаточная статистика
Примеры:

🔹Полнота#
Статистика \(T(X) \, \, X = X_1, X_2, ..., X_n\) называется полной, если \(\forall \varphi(\cdot) выполнено:\)
Если функция правдоподобия, построенная по выборке \(X=X_1, X_2, ..., X_n\) представима в виде:
то говорят, что выборка пренадлежит экспоненциальному семейству.
Общий вид распределений из семества экспоненциальных распределений:
Теорема о полносте экспоненциальных семейств
Если \(b_i(\theta)\) покрывает \(k-\)мерный параллелепипед \(\Theta\), то \(T = (T_1(x), T_2(x), ..., T_n(x))\) полная достаточная статистика.
Пример:
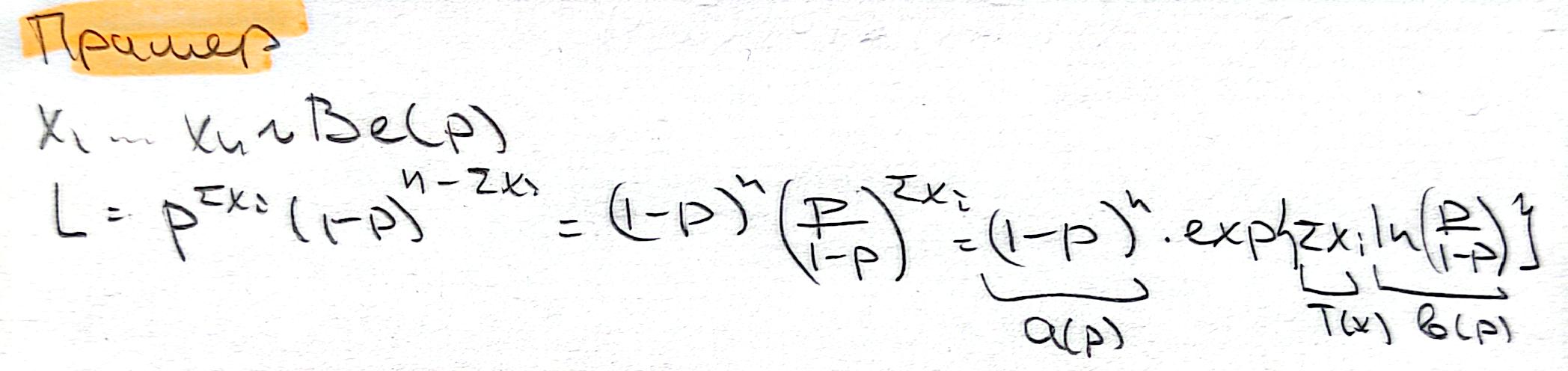
🔹Оптимальность и ассимптотическая нормальность#
Статистика \(T(X) \,\,\,\, X=X_1, X_2, ..., X_n\) называется оптимальной оценкой для \(\tau(\theta)\), если она несмещена, т.е.\(\mathbb{E}[T(\=X)] = \tau(\theta)\) и для любой другой оценки \(T_i(X) \neq T(X): \, \mathbb{E}[T_i(X)] = \tau(\theta)\) выполнено
Оценка \(T(X) \,\,\,\, X=X_1, X_2, ..., X_n\) называется ассимптотически нормальной для \(\tau(\theta)\), если
🔹Метод моментов#
Метод моментов — это способ нахождения оценок параметров распределения, при котором теоретические моменты распределения приравниваются к выборочным моментам. Оценки, полученные такими спососбом, являются несмещенными и состоятельными.
Пусть случайная величина \( X\) имеет распределение, зависящее от неизвестного параметра (или вектора параметров) \( \theta = (\theta_1, \theta_2, \ldots, \theta_k)\)
и мы наблюдаем выборку: \( X_1, X_2, \ldots, X_n\)
Теоретическим (начальным) моментом \(j\)-го порядка называется:
Он выражается через параметры распределения \( \theta \), то есть \( \mu_j' = \mu_j'(\theta_1, \ldots, \theta_k)\)
Выборочные моменты можно вычислить по выборке:
📎Основная идея Основная идея метода моментов заключается в том, чтобы приравнять выборочные моменты теоретическим:
Решая эту систему уравнений относительно неизвестных параметров, получаем оценки:
Эти оценки называются оценками, найденными методом моментов. Иногда вместо начальных моментов \( \mu_j'\) удобно использовать центральные моменты:
и соответствующие им выборочные аналоги:
Пример:
Пусть \( X \sim \text{Exp}(\lambda)\) — экспоненциальное распределение.
Тогда теоретическое математическое ожидание:
А выборочное:
Приравниваем:
Отсюда получаем оценку параметра:
🔹 Метод максимального правдоподобия (ММП)#
Метод максимального правдоподобия (ММП) — это способ оценки неизвестных параметров распределения, основанный на принципе:
наиболее правдоподобным считается то значение параметра, при котором наблюдаемая выборка имеет наибольшую вероятность появиться.
📎Оценки максимального правдоподобия (ММП) обладают важными свойствами, включая состоятельность, асимптотическую нормальность и асимптотическую эффективность. Они также обладают свойством инвариантности. Эти свойства означают, что с увеличением объема выборки оценки ММП сходятся к истинным значениям параметров, а их точность увеличивается до предельной минимальной дисперсии.
Пусть \(X_1, X_2, \ldots, X_n\) — независимые наблюдения случайной величины \( X \), распределённой по закону \( f(x; \theta) \), где \( \theta \) — неизвестный параметр (или вектор параметров):
Функцией правдоподобия называется:
Это вероятность (или плотность) получить именно наблюдённую выборку при фиксированном \( \theta \).
Часто удобнее работать с логарифмом функции правдоподобия:
Так проще вычислять производные и решать уравнения.
📎Основная идея Основная идея метода заключается в том, чтобы найти значение параметра \( \hat{\theta} \), при котором функция правдоподобия максимальна:
Для нахождения максимума вычисляем производные (градиент) и приравниваем их нулю:
Решая эту систему, получаем оценки:
Примеры:

🔹Информация Фишера#
Функцией вклада выборки \(X=X_1, X_2, ..., X_n\) c параметром \(\theta\) называется:
Информацией Фишера о параметре \(\theta\) содержащейся в выборке \(X=X_1, X_2, ..., X_n\) называется:
или
📎 Замеччание Информация Фишера показывает, насколько “информативна” выборка относительно неизвестного параметра. Она измеряет, насколько точно можно оценить параметр по наблюдениям: чем больше информация Фишера, тем меньше разброс (дисперсия) любой несмещённой оценки этого параметра.
Если плотность сильно меняется при небольшом изменении параметра то выборка “много говорит” о параметре → информация Фишера велика.
Если почти не меняется → информации мало.
Примеры:

🔹Нераветсво Рао-Крамера#
📎Условия регулярности:
1-го порядка: \(\int{\frac{\partial}{\partial \theta}}L(X, \theta)dX = 0\) 2-го порядка: \(\int{T(X)\frac{\partial}{\partial \theta}}L(X, \theta)dX = \tau'(\theta)\)
Пусть выполнены условия регулярности 1-го и 2-го порядка, тогда
В случае, если \(T(X)\) - несмещенная оценка для \(\tau(\theta)\), неравенство будет выглядеть следующим образом:
Если \(T(X) - \tau(\theta) = a(\theta) \frac{\partial ln L(X, \theta)}{\partial \theta}\), тогда \(T(X)\) называется эффективной оценкой \(\tau(\theta)\).
🔹Эффективность#
Пусть \(X_1, X_2, \ldots, X_n \) — выборка из распределения с плотностью \(f(x; \theta) \), и пусть \(T = T(X_1, X_2, \ldots, X_n) \) — несмещённая оценка функции параметра \(\tau(\theta) \).Тогда оценка \(T \) называется эффективной, если она достигает нижней границы неравенства Рао–Крамера, то есть
где \(i_\theta \) — информация Фишера:
📎Эффективная оценка — это наилучшая (в смысле минимальной дисперсии) несмещённая оценка параметра.
Если такая оценка существует, то она реализует максимум информации Фишера, содержащейся в данных о параметре \(\theta \).
Примеры
*Оценка параметра ММП
