🟦Линейная регрессия#
Код тут.
Пусть \(\mathbb{Y} \in \mathbb{R}, \mathbb{X} \in \mathbb{R}^d, x = \{ x \in \mathbb{X}: \,\,x = (x_1, ..., x_d)\}\) - признаки.
🔹Общий вид#
Модель линейной регрессии будет иметь вид: \(a(x) = w_0 + \sum_{j=1}^d w_j x_j\)
Пусть \( X' = \begin{pmatrix} x_1 \\ x_2 \\ ... \\ x_d \end{pmatrix} \in \mathbb{R}^d, \,\,\,\,\,\,\,\,\,\,\,\,\, w = \begin{pmatrix} w_1 \\ w_2 \\ ... \\ w_d \end{pmatrix} \in \mathbb{R}^d \)
Тогда нашу модель можем переписать в следующем виде: \(a(x) = w_0 + \langle w, X' \rangle\)
Сделаем некоторое предположение. Будем считать, что у нас гарантированно есть константный признак, т.е. \(x_0\equiv1\). Тогда
🔹Изменение ошибки в задачах регрессии#
\(L(y, z)\) - функция потерь. \(Q(a, \mathbb{X}) = \frac{1}{l}\sum_{i=1}^lL(y_i, a(x_i))\)
MSE

\(L(y, z) = (y-z)^2\)
\(Q(a, \mathbb{X}) = \frac{1}{l}\sum_{i=1}^l\left( a(x_i) - y_i\right)^2\)
MAE

\(L(y, z) = |y-z|\)
\(Q(a, \mathbb{X}) = \frac{1}{l}\sum_{i=1}^l\left| a(x_i) - y_i\right|\)
Huber-loss

\(L(y, z) = \begin{cases} \frac{1}{2}(y-z), \,\, |y-z| <d \\ d\left(|y-z| - \frac{1}{2}d\right),\,\, |y-z| \geq d \end{cases}\)
Но ее основной минус в том, что у нее есть проблемы со вторыми производными, что плохо для некоторых моделей машинного обучения, которые используют методы оптимизации 2-го порядка.
Log-Cosh

\(L(y, z) = log \,\,ch (y-z)\)
Она дважды дифференцируема, поэтому фиксит проблему со вторыми производными.
MAPE - относительная функция потерь

\(L(y, z) = \left|\frac{y - z}{y}\right|\)
\(Q(a, \mathbb{X}) = \frac{1}{l}\sum_{i=1}^l \frac{1}{|y_i|}\left| a(x_i) - y_i\right|\)
Более интерпретируема. Например, если \(L = 2\), то мы ошибаемся в 3 раза.
Хороши при разным масштабах целевой переменной.
По сути MAE с весами. Чем больше \(|y_i|\), тем менее страшно ошибиться.
SMAPE - относительная функция потерь

\(L(y, z) = \left|\frac{y - z}{(y+z)/2}\right|\)
🔹Обучение линейных моделей#
Перед нами стоит следующая задача:
\( \frac{1}{l} \sum_{i=1}^{l} ( \langle w, x_i\rangle - y_i)^2 \to \min_{w\in \mathbb{R}^d} \,\,\,\,\,(*) \)
Введем следующие обозначения:
\( X_{l \times d} = \begin{pmatrix} x_{11} & x_{12} & ... & x_{1d}\\ x_{21} & x_{22} & ... & x_{2d}\\ &&... \\ x_{l1} & x_{l2} & ... & x_{ld} \end{pmatrix}, \,\,\,\,\,\, w = \begin{pmatrix} w_1 \\ w_2 \\ ... \\ w_d \end{pmatrix} \,\,\,\,\,\, y = \begin{pmatrix} y_1 \\ y_2 \\ ... \\ y_l \end{pmatrix} \)
Тогда
\(X_{l\times d}w_{d\times 1} = \begin{pmatrix} \langle w, x_1\rangle \\ \langle w, x_2\rangle \\ ... \\ \langle w, x_l\rangle \end{pmatrix}_{l\times 1} \)
Перепишем \((*)\) в векторном виде:
\(Q(w) = \frac{1}{l} \left\lVert Xw-y \right\rVert_2^2 \to \min_{w}\)
Дальше можем посчитать градиент, приравнять его к 0 и получить следующее аналитическое решение:
\(\nabla Q(w) = 0\)
\(\boxed{w_* = (X^TX)^{-1}X^Ty}\)
В чем сложности?
Матрица может быть вырожденной;
Обращение матрицы дорого стоит;
Если \(L(y, z)\) более хитрая, то аналитически найти решение не выйдет.
Никто не пользуется аналитическими решениями. Как правило оптимальные веса находят с помощью градиентного спуска.
Алгоритм следующий:
\(w^{(0)}\) - инициализация
\(w^{(k)} = w^{(k-1)} - \eta \nabla Q(w^{(k-1)})\)
Шаг 2 до тех пор, пока не будут выполнены условия останова.
🔹Недообучение и переобучение#

Как правило если модель переобучена, то веса большие и наоборот.
Идея: запретить большие веса!
\( Q(w) + \alpha R(w) \to \min_w \)
где \(R(w)\) - регуляризатор, а \(\alpha\) - коэффициент регуляризации.
Регуляризаторы бывают разные, например:
l1: \(\left\lVert w \right\rVert_1 = \sum_{j=1}^d |w_j|\)
l2: \(\left\lVert w \right\rVert_2^2 = \sum_{j=1}^d w_j^2\)
Данные надо масштабировать, чтобы модели получались корректными.
Нейминг:
\(\frac{1}{l} \sum_{i=1}^{l} ( \langle w, x_i\rangle - y_i)^2 + \left\lVert w \right\rVert_2^2\to \min_{w}\) - Ridge регрессия
\(\frac{1}{l} \sum_{i=1}^{l} ( \langle w, x_i\rangle - y_i)^2 + \left\lVert w \right\rVert_1 \to \min_{w}\) - Lasso регрессия
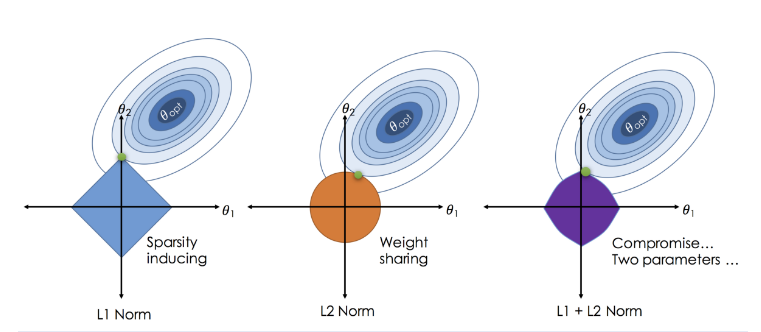
Как правило, при использовании lasso регрессии многие веса зануляются в зависимости от \(\alpha\).
🟦Линейная классификация#
Пусть \(a(x) = sgn(\langle w, x \rangle)\) - знак какой-то линейной модели.
\(Q(a, x, y) = \frac{1}{n} \sum_{i=1}^{n}\left[ a(x_i) \neq y_i\right] = \frac{1}{n} \sum_{i=1}^{n}\left[ y_i \langle w, x_i \rangle < 0\right]\)
Определим \(y_i \langle w, x_i \rangle = M_i\) - оступ на i-ом объекте. \(L(M_i) = \left[M_i < 0\right]\) - индикатор того, попали ли мы в класс. Т.о, если \(M_i < 0\), то \(L(M_i) = 1\), то класс предсказан неверно. (синяя линия)
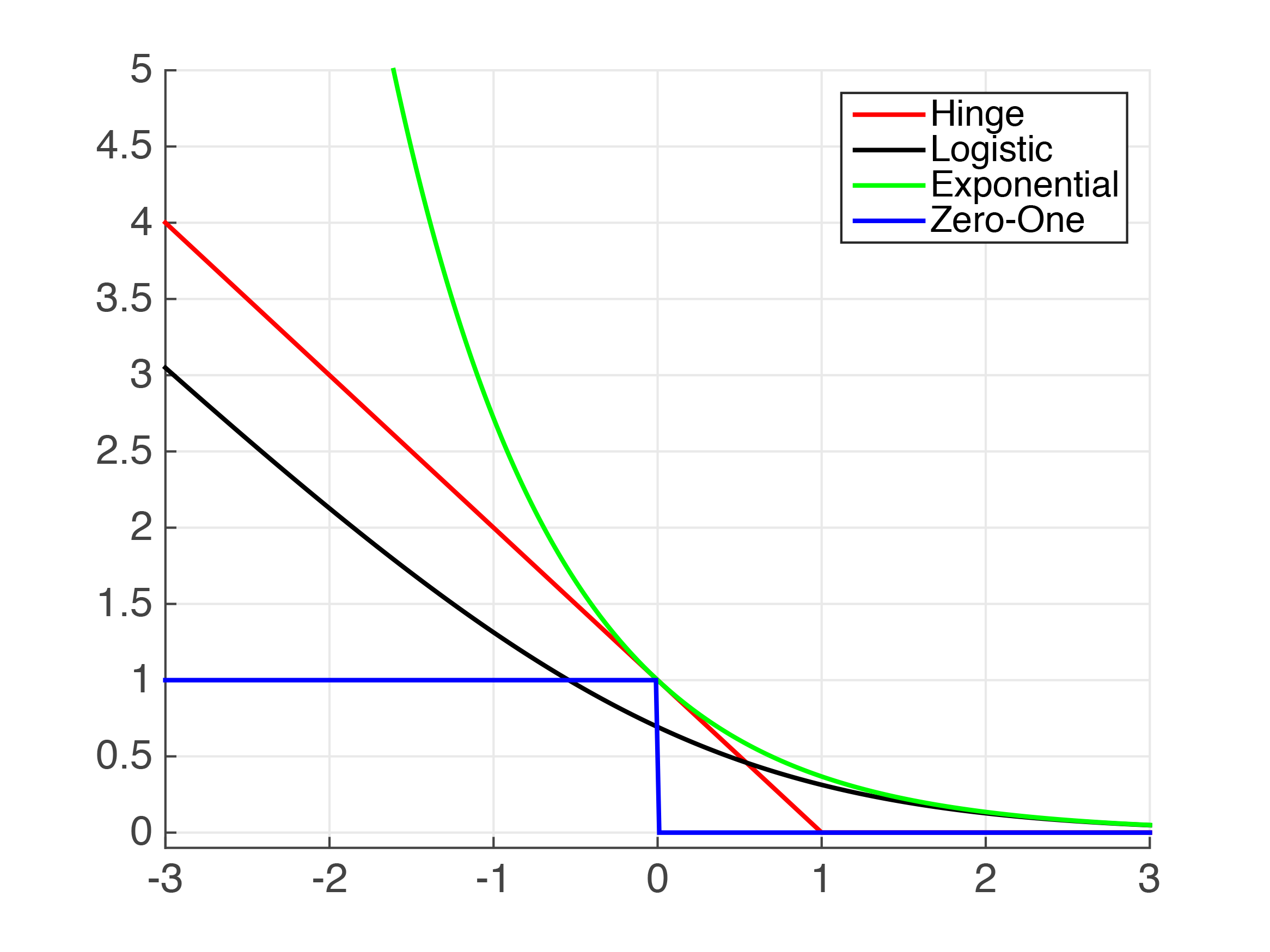
\(\hat{L}(M) = log(1+exp(-M))\) - logistic
\(\hat{L}(M) = max(0, 1-M)\) - hinge
\(\hat{L}(M) = exp(-M)\) - exponential
🔹Логистическая регрессия#
Хотим научиться оценивать вероятности классов, т.о., если модель говорить, что вероятность положительного класса равна 95%, то это значит, что если взять все объекты с вероятностью 95%, то 95% из них действительно будут объектами положительного ккласса.
Пусть модель \(b\) - корректно оценивает вероятности. Возьмем все объекты с \(b(x) = p\) и среди них доля положительных будет \(p\).
Пусть \(x_1, ..., x_n\) и \(b(x_1) = b(x_2)=...=b(x_n) = b\), тогда
\(\argmin_{b \in [0, 1]} \frac{1}{n} \sum_{i=1}^n L(y_i, b) = \frac{1}{n} \sum_{i=1}^n \left[y_i = +1\right]\)
т.е. говорим, что наша функция потерь хорошо оценивает вероятности, если для какой-то группы объектов оптимально выдвать долю положительных в качестве прогноза.
Пусть \(n \to \infty\):
\(\frac{1}{n} \sum_{i=1}^n L(y_i, b) = \frac{1}{n} \sum_{i=1}^n \left[y_i = +1\right] L(+1, b) + \frac{1}{n} \sum_{i=1}^n \left[y_i = -1\right] L(-1, b) = L(+1, b) \frac{1}{n} \sum_{i=1}^n \left[y_i = +1\right] + L(-1, b) \frac{1}{n} \sum_{i=1}^n \left[y_i = -1\right]\)
\(\argmin_{b \in [0, 1]} \mathbb{E}_y \left[ L(y, b) | x \right] = p(y = +1|x)\)
Пусть \(y_i\) - с.в. с распределением Бернулли. А \(b(x_i)\) оценивает вроятность \(p(y_i=1|x)\)
\(\prod_{i=1}^lb(x_i)^{[y_i = 1]}(1-b(x_i))^{[y_i = -1]} \to \max_b\)
Прологарифмируем:
\(-\sum_{i=1}^l[y_i=1]log(b(x_i)) + [y_i=-1]log(1-b(x_i)) \to \min\)
У нас \(b(x) = \sigma(\langle w, x\rangle)\), где \(\sigma(z) = 1/(1+e^{-z})\)
Если подставить в logloss, то получим
\(\frac{1}{l} \sum_{i=1}^l log(1+\exp(-y_i\langle w, x_i\rangle)) \to \min_w\) - логистическая ФП.
🔹SVM#
\(\hat{L}(M) = max(0, 1-M)\)
Пусть \(a = sign(\langle w, x \rangle + w_0)\)
Заметим, что если умножить все на \(\alpha\), то ничего не поменяется
\(a(x) = sign(\langle \alpha w, x\rangle) + \alpha w_0\)
Рассмотрим \(\min_{x_i \in X}|\langle w, x_i\rangle + w_0| = 1\) - можно добиться масштабированием. Будем считать, что это выполнено.
Расстояние от плоскости до точки \(x\): \( \rho(a, x) =\frac{|\langle w, x\rangle + w_0|}{\lVert w\rVert^2}\)
Тогда \(\min_{x_i \in X} \rho(a, x_i) = \min_{x_i \in X}\frac{|\langle w, x\rangle + w_0|}{\lVert w\rVert^2} = \frac{1}{\lVert w\rVert^2}\) из нашего условия сверху.
Таким образом SVM для разделимого случая:
Сведем к задаче минимизации и упростим:
Линейно неразделимый случай.
Штрафуем за большие веса и за то, что модель позволяет себе ошибаться.
По сути, первое слагаемое - это регуляризатор, а сумма - это функционал ошибки \(\hat{L}(y, z) = max(0, 1-yz)\)
🔹Метрики качества классификации#
Матрица ошибок
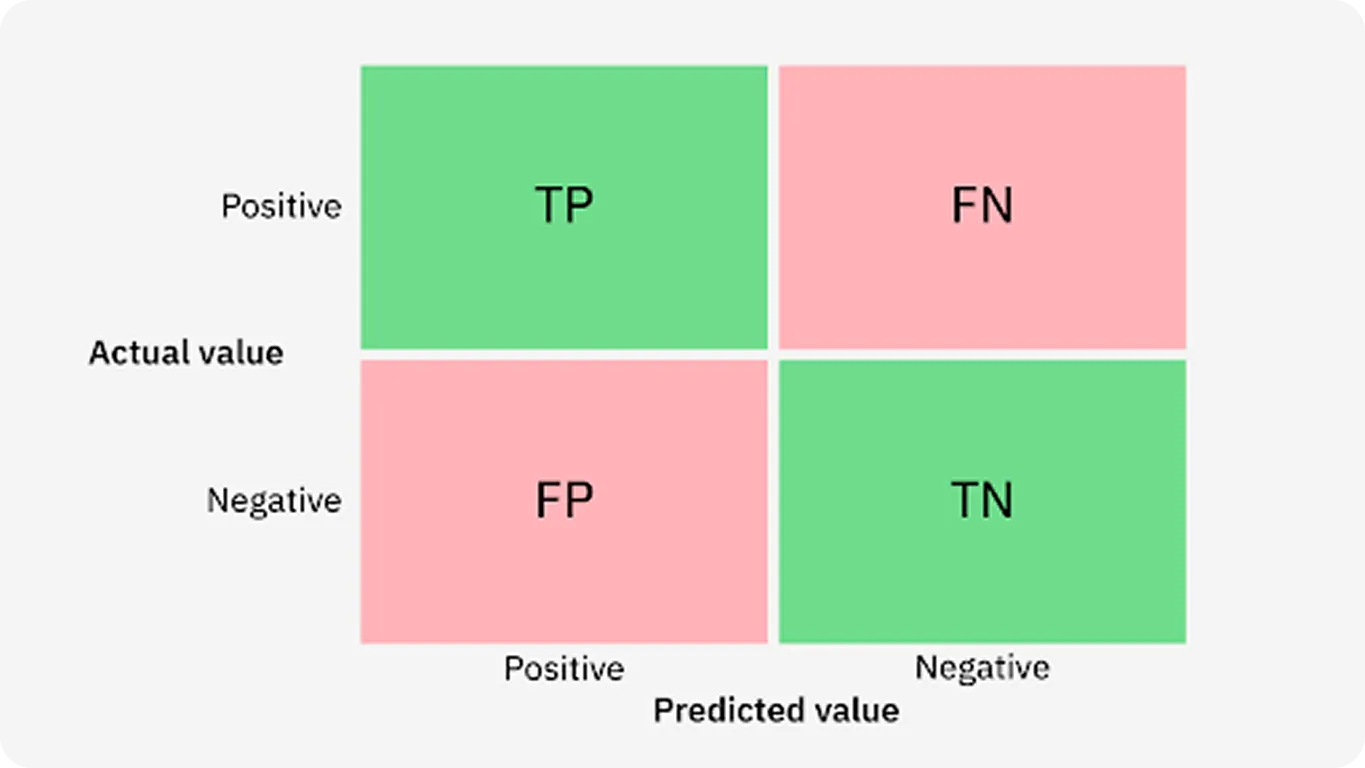
Из нее получаются все следующие метрики качества:
\(Acc = \frac{TN + TP}{TN + TP + FP + FN}\)
\(Precision = \frac{TP}{TP + FP}\) - сколько объектов из названных 1, действительно 1.
\(Recall = \frac{TP}{TP + FN}\) - сколько объектов положительного класса из всех мы нашли.
\(TPR = \frac{TP}{TP + FN} = Recall\)
\(FPR = \frac{FP}{FP + TN}\) - ошибка 1 рода.
\(FNR = \frac{FN}{FN + TP}\) - ошибка 2 рода
Объединение Precision и Recall
График |
Формула |
|---|---|
\(\overline{TP} = \frac{1}{k} \sum_{k=1}^K TP_k\) |
\(Precision_k = \frac{TP_k}{TP_k + FP_k}\) |
\(Precision = \frac{\overline{TP}}{\overline{TP} + \overline{FP}}\) |
\(Precision = \frac{1}{k} \sum_{k=1}^K precision_k\) |
Обращаем больше внимания на большие перекосы |
Все классы вносят общий вклад |
🔹Многоклассовая классификация#
Сведение к серии бинарных задач#
One VS All
Для каждого класса строим свой классификатор, который отделяет свой класс от всех остальных. А после выбираем тот класс, класификатор которого уверен в том, что объект принадлежит его классу.
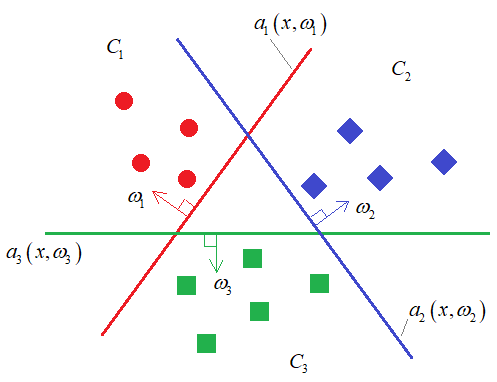
\(b_k(x) = \langle w_k, x\rangle + w_0\)
Обучем на \(X_k = (x_i, [y_i = k])_{i=1}^l\)
\(a(x) = \argmax_{k = 1, ..., K} b_k(x)\)
Минус в том, что надо обучать много моделей, если много классов.
Но основная проблема в том, что модели несогласованы, т.е. не знают ничего друг о друге при обучении.
All VS All
Строим \(C_n^k\) классификаторов, которые учим различать 2 класса. А потом устраиваем своего рода турнир. Выбираем класс, который победил больше всего раз.
\(a_{i, j} (x) обучем на X_{i, j} = \{(x_n, y_n) | y_n = i \,\,\, or \,\,\,j\}\).
\(a(x) = \argmax_{k=\overline{1, k}} \sum_{i \neq k} [a_{kj}(x) = k]\)
Прямые методы#
Например многоклассовая log-регрессия.
\(b_k(x) = \langle w_k, x\rangle + w_{0k}\)
Для каждого объекта находим вектор \(b(x) = (b_1(x), ..., b_k(x))\)
Берем \(softmax(z_1, z_2, ...z_k) = \left(\frac{e^z_1}{\sum_k e^z_k}, ..., \frac{e^z_k}{\sum_k e^z_k}\right)\)
т.е. \(P(y=k|x) = \frac{\exp(\langle w_k, x\rangle + w_{0k})}{\sum_{j=1}^k \exp(\langle w_j, x\rangle + w_{0j})}\)
Тогда функционал качества будет выглядеть следующим образом:
\(\sum_{i=1}^llogP(y = y_i|x_i) \to \max\)
Метрики качества многоклассовой классификации#
\(Acc = \frac{1}{l} \sum_{i=1}^l [a(x_i) = y_i]\)
Микро-усреднение |
Макро-усреднение |
|---|---|
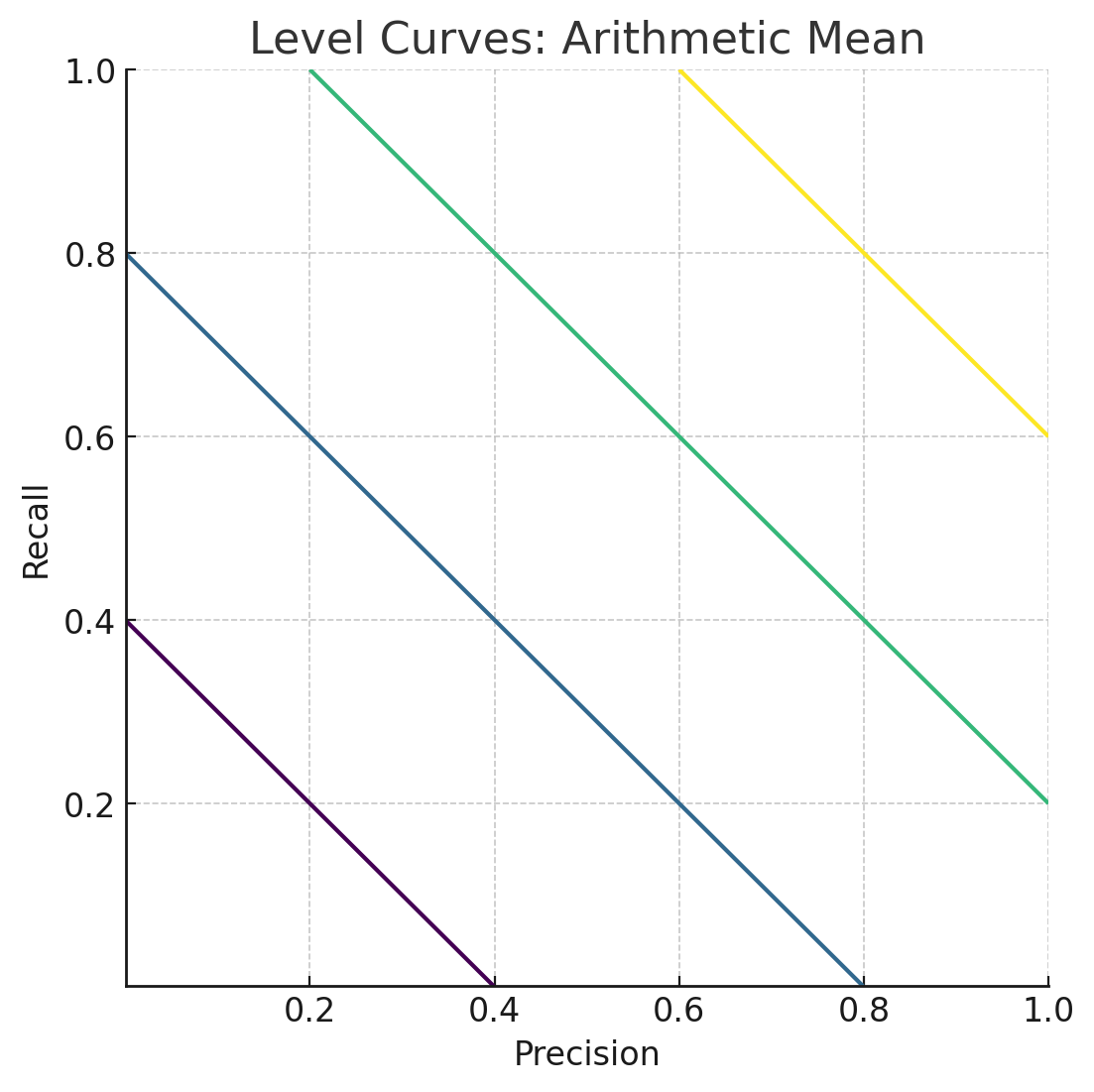 |
\(A = \frac{Precision+Recall}{2}\) |
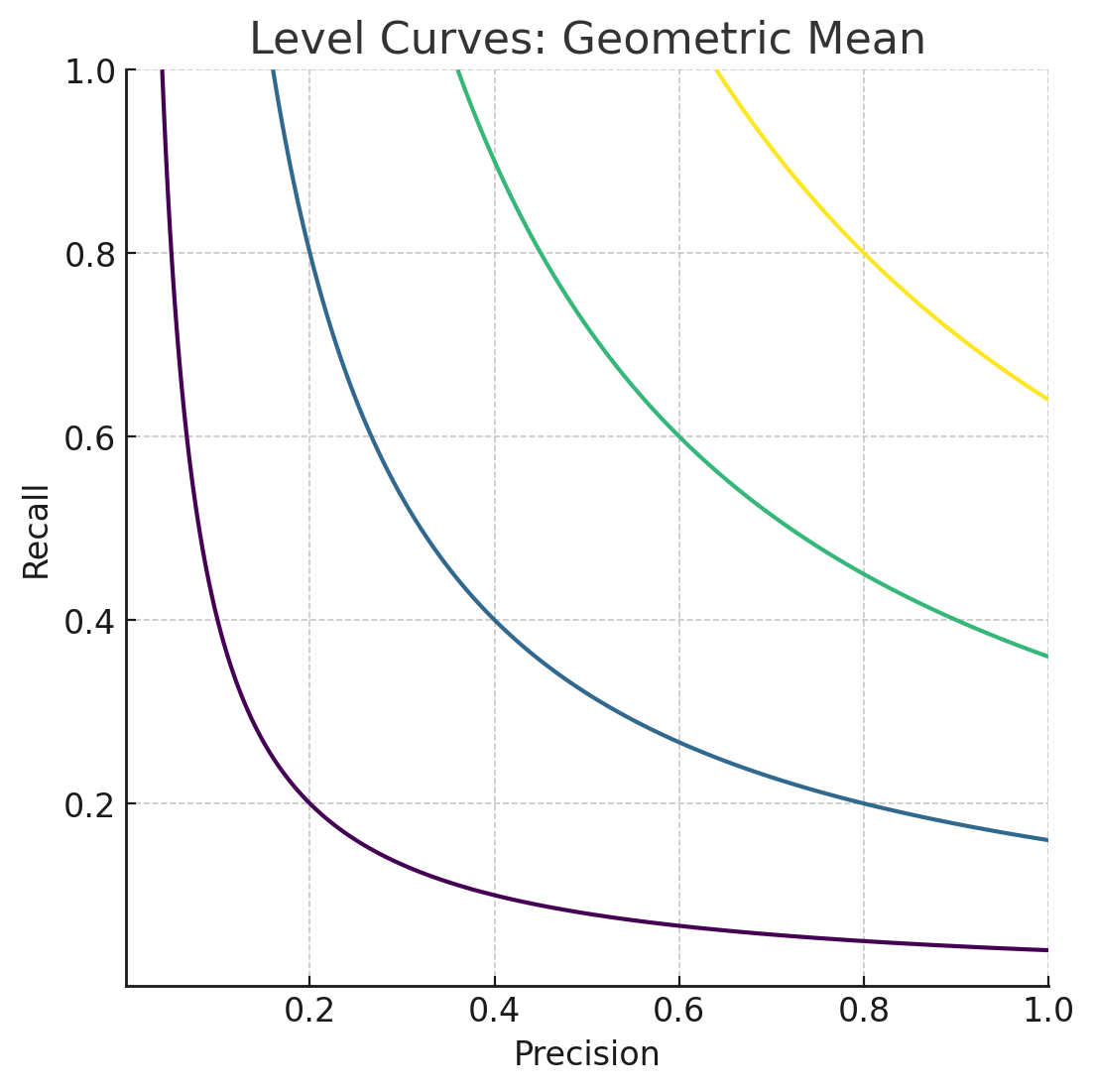 |
\(A = \sqrt{Precision \cdot Recall}\) |
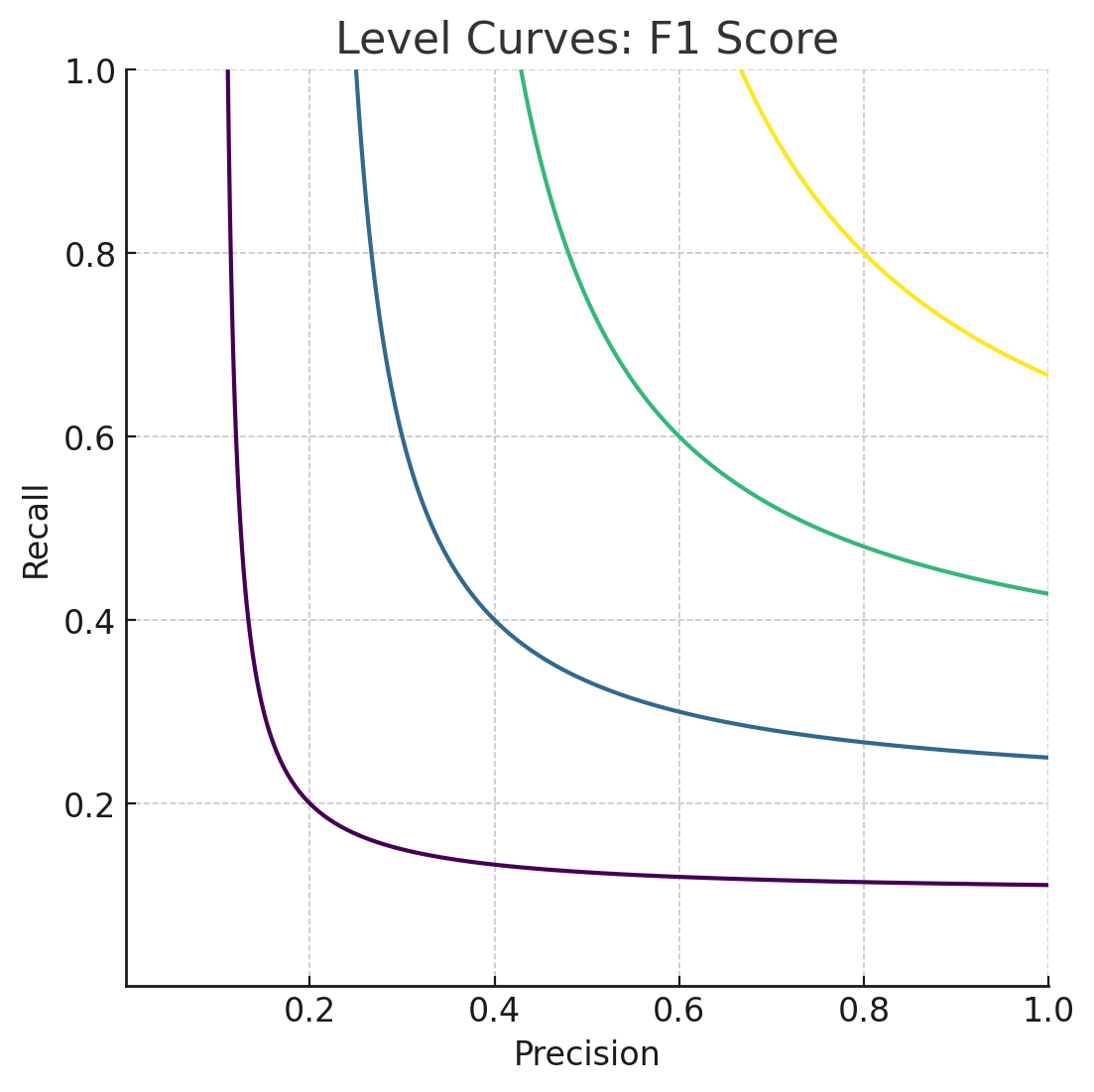 |
\(F_1 = \frac{2Precision \cdot Recall}{Precision + Recall}\) |
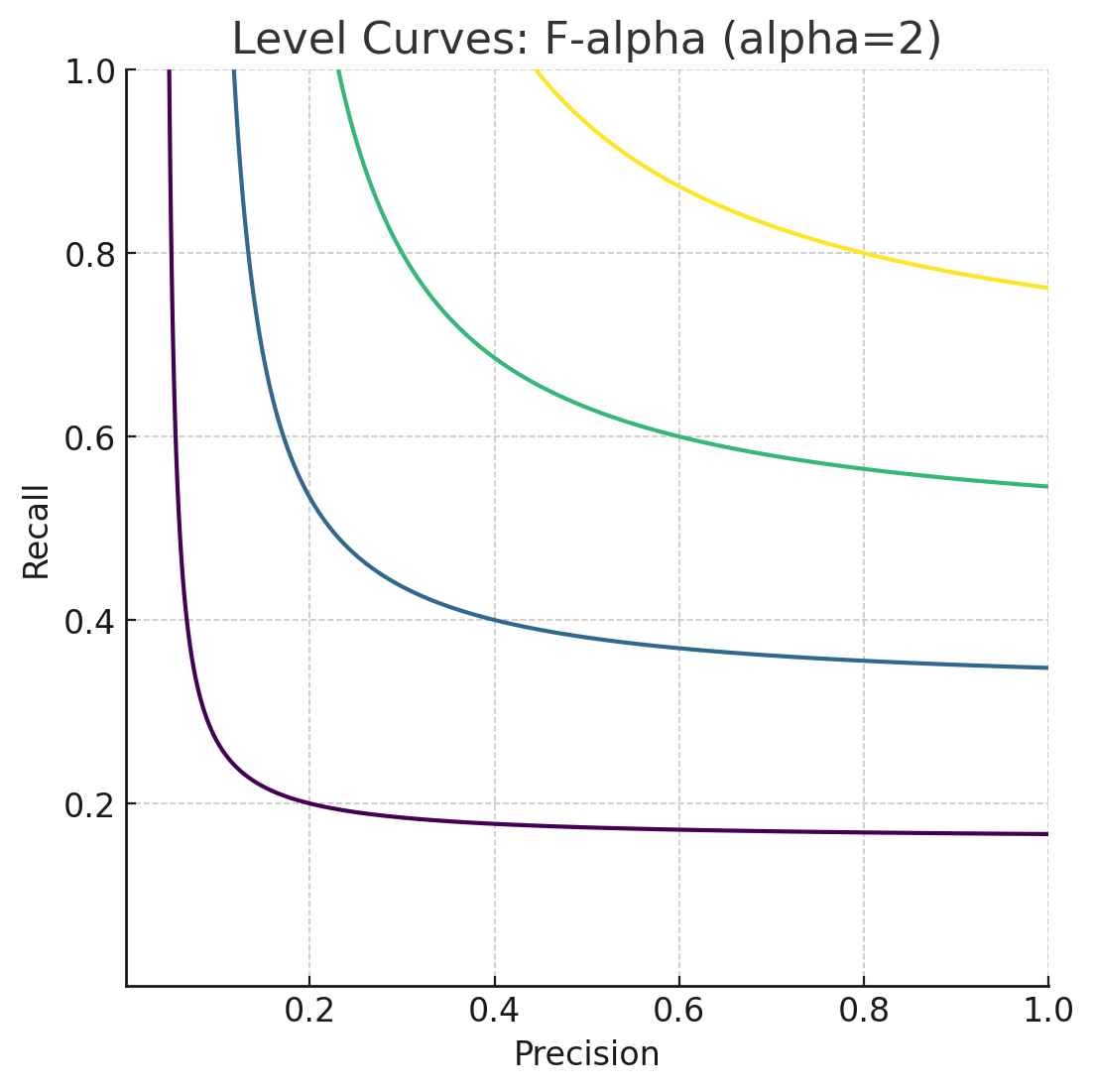 |
\(F_1 = \frac{(1+\alpha^2)Precision \cdot Recall}{\alpha^2Precision + Recall}\) |
Площади под кривыми Пусть модель \(a(x) = sign(b(x) -t)\), где \(b(x)\) - уверенность в +1, \(t\) - порог.
Как измерить качество \(b(x)\)?
Упорядочим объекты по уверенности модели в принадлежности к положительному классу, т.e.
\(b(x)\) |
\(y_i\) |
|---|---|
100 |
1 |
80 |
-1 |
73 |
1 |
… |
… |
1 |
1 |
-1 |
-1 |
… |
… |
-100 |
1 |
Перебираем все пороги \(t\) и по отсеченным объектам считаем нужные метрики и отмечаем их на графике:
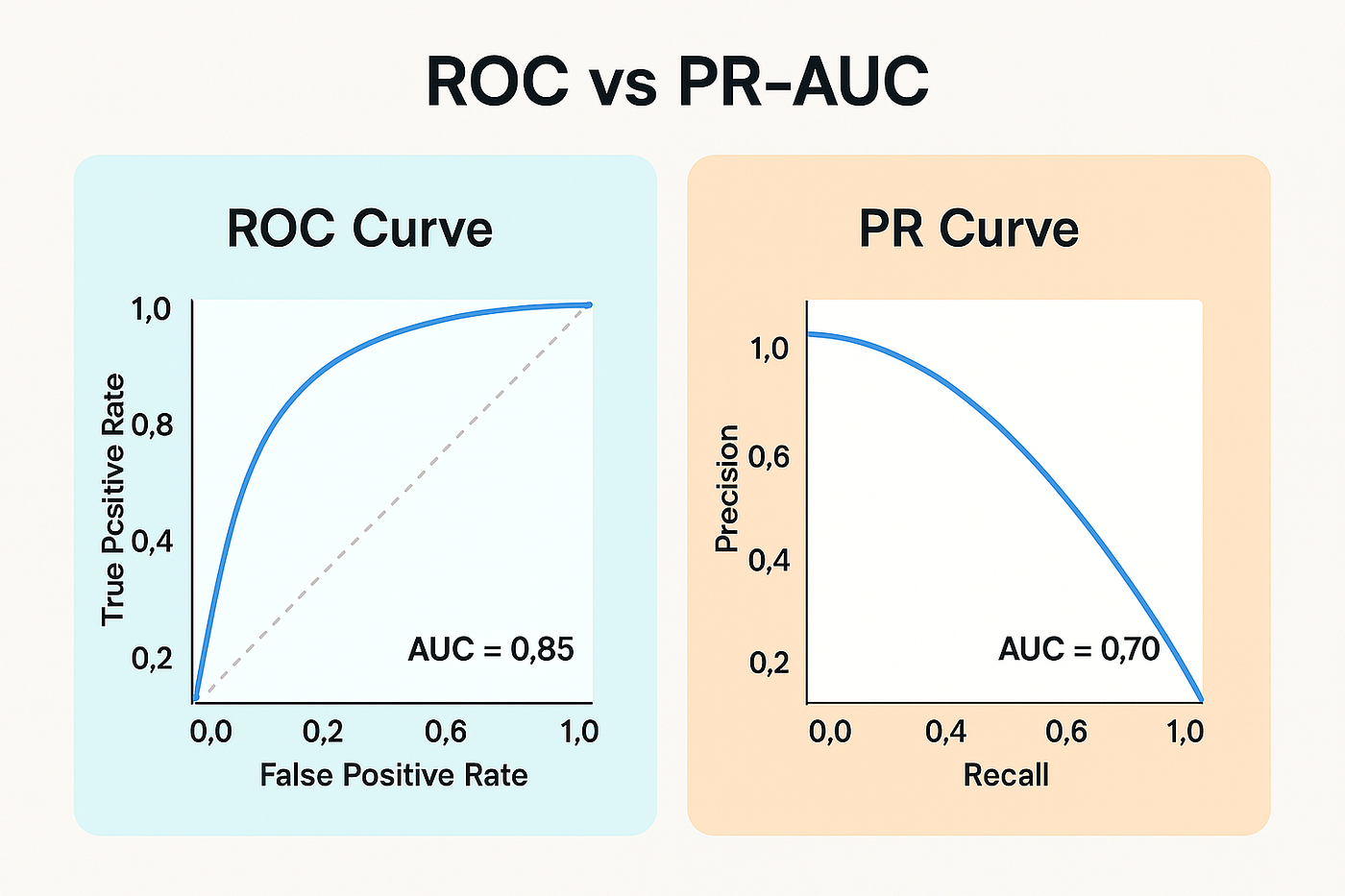
Считаем площади.
PR показывает, насколько модель хорошо находит положительный класс, когда он редкий. А roc - насколько хорошо модель разделяет положительные и отрицательные примеры независимо от их количества.