🟦Проверка гипотез#
Ститистической гипотезой называют любое предположение о распределении и свойствах случайной величины.
Статистическим критерием называют правило, позволяющее по реализации выборки отклонить или не отклонить нулевую гипотезу с заданным уровнем значимости.
Уровнем значимости называют вероятность отклонить H0, когда она верна (ошибка 1 рода).
Статистическая мощность - вероятность отклонения H0, когда верна альтернативная.
Критическая область - область выборочного пространста, при попадании в которую нулевая гипотеза отклоняется.
🔹t-критерий Стьюдента#
Одновыборочный t-критерий
Пусть \( X_1, X_2, \ldots, X_n \) — независимая выборка из нормального распределения
где \( \mu \) — неизвестное математическое ожидание, \( \sigma^2 \) — неизвестная дисперсия.
Нужно проверить гипотезу:
Выборочное среднее:
Выборочная дисперсия:
Тогда t-статистика определяется как:
Если гипотеза \( H_0 \) верна, то
где \( t_{n-1} \) — распределение Стьюдента с \( n-1 \) степенями свободы.
Двухвыборочный t-критерий (равные дисперсии)
Пусть есть две независимые выборки:
Проверяем гипотезу:
Общая (объединённая) выборочная дисперсия:
Тогда
t-критерий для неравных дисперсий (Уэлча)
Если предполагать, что \( \sigma_1^2 \neq \sigma_2^2 \),
то статистика:
имеет распределение, приближённое к \( t_{\nu} \), где эффективное число степеней свободы вычисляется по формуле Уэлча:
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
np.random.seed(40)
# --- Параметры ---
mu_true = 5 # истинное среднее
sigma_true = 2 # истинное стандартное отклонение
n = 50 # размер выборки
alpha = 0.05 # уровень значимости
# --- Генерация выборки ---
sample = np.random.normal(mu_true, sigma_true, n)
# Проверяем гипотезу H0: mu = mu0
mu0 = 5
# --- Вычисление t-статистики ---
x_bar = np.mean(sample)
s = np.std(sample, ddof=1)
t_stat = (x_bar - mu0) / (s / np.sqrt(n))
# --- p-value ---
p_value = 2 * (1 - stats.t.cdf(abs(t_stat), df=n-1))
# --- Критическое значение ---
t_crit = stats.t.ppf(1 - alpha/2, df=n-1)
print(f"Выборочное среднее: {x_bar:.3f}")
print(f"Стандартное отклонение: {s:.3f}")
print(f"t-статистика: {t_stat:.3f}")
print(f"Критическое значение (двустороннее): ±{t_crit:.3f}")
print(f"p-value: {p_value:.4f}")
if abs(t_stat) > t_crit:
print("❌ Отвергаем H0: среднее отличается от μ₀")
else:
print("✅ Не отвергаем H0: нет оснований считать, что среднее отличается от μ₀")
# --- Визуализация ---
x = np.linspace(-4, 4, 400)
t_pdf = stats.t.pdf(x, df=n-1)
norm_pdf = stats.norm.pdf(x, 0, 1)
plt.figure(figsize=(8, 5))
plt.plot(x, t_pdf, label=f"t({n-1}) распределение", linewidth=2)
plt.plot(x, norm_pdf, '--', label="N(0,1)", color='gray')
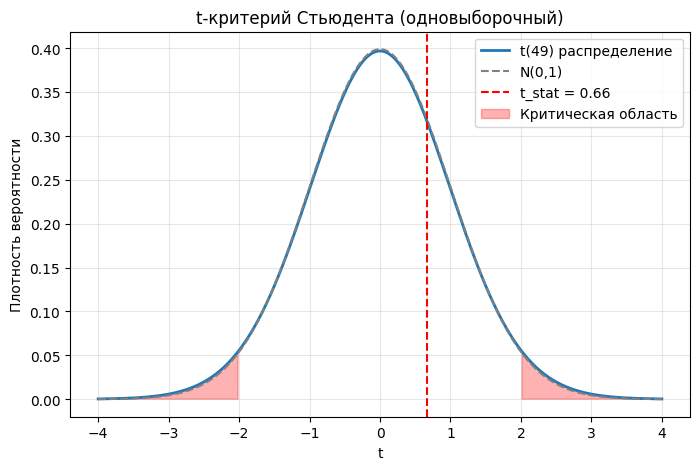
plt.axvline(t_stat, color='r', linestyle='--', label=f"t_stat = {t_stat:.2f}")
plt.fill_between(x, 0, t_pdf, where=(x > t_crit) | (x < -t_crit), color='red', alpha=0.3, label="Критическая область")
plt.title("t-критерий Стьюдента (одновыборочный)")
plt.xlabel("t")
plt.ylabel("Плотность вероятности")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
Выборочное среднее: 5.157
Стандартное отклонение: 1.686
t-статистика: 0.660
Критическое значение (двустороннее): ±2.010
p-value: 0.5123
✅ Не отвергаем H0: нет оснований считать, что среднее отличается от μ₀
🔹 U-критерий Манна–Уитни#
📎 U-критерий Манна–Уитни — это непараметрический тест, применяемый для проверки гипотезы о распределений двух независимых выборок.
Он является аналогом двухвыборочного t-критерия Стьюдента, но не требует нормальности распределений и устойчив к выбросам.
Пусть заданы две независимые выборки: $\( X_1, X_2, \ldots, X_{n_1}, \quad Y_1, Y_2, \ldots, Y_{n_2}. \)$
Проверяется гипотеза:
Алгоритм вычисления статистики
Объедини обе выборки в одну совокупность из \( n = n_1 + n_2 \) наблюдений.
Отсортируй все элементы по возрастанию и присвой ранги от 1 до \( n \).
Если есть одинаковые значения (связи), присваиваются средние ранги.Найди сумму рангов первой выборки: $\( R_X = \sum_{i=1}^{n_1} r(X_i), \)\( где \) r(X_i) \( — ранг элемента \) X_i $.
Вычисли статистику: $\( U_X = R_X - \frac{n_1 (n_1 + 1)}{2}. \)\( Аналогично можно вычислить \) U_Y \(: \)\( U_Y = R_Y - \frac{n_2 (n_2 + 1)}{2}. \)$
📎 Связь между ними: $\( U_X + U_Y = n_1 n_2. \)$
Критическая статистика
Выбирают минимальное из двух значений:
Дальше находим критическое значение U-критерия при заданных \(n_1\) и \(n_2\) и сравниваем с полученным.
Нормальность U-статистики
Если верна H0, то статистика будет иметь распределение
Пример:
Наблюдения X |
Наблюдения Y |
|---|---|
8 |
3 |
7 |
6 |
6 |
5 |
Общая выборка: 3, 5, 6, 6, 7, 8
Присвоим ранги:
3→1, 5→2, 6→3.5, 6→3.5, 7→5, 8→6
По таблице критических значений (для \( n_1 = n_2 = 3 \), \(\alpha = 0.05\)) → \( U_{crit} = 2 \).
Так как \( U = 0.5 < 2 \), отвергаем \( H_0 \).
🔹Критеий отношения правдоподобия (hard ml)#
Что же делать, когда для гипотезы нет критерия?
Введем функцию правдоподобия \(L(\theta) = \prod_{i=1}^n f(X_i|\theta)\)
Гипотезы: \(H_0: \theta \in \Theta_0\) \(H_1: \theta \notin \Theta_0\)
Пример:
\(X_1, X_2, ..., X_n = N(\mu, \sigma^2)\)
\(\theta = (\mu, \sigma^2)\), тогда \(\Theta = \{\mu: \mu \in [0, 5], \sigma^2: \sigma^2 \in [1, 2]\}\)
Тогда можно вести такую статистику, как отногение правдоподобия
где \(\hat{\theta} - ОМП\), а \(\hat{\theta_0}\) - ОМП при условии \(\theta \in \Theta\).
Допустим \(\theta= (\theta_1, ..., \theta_q, \theta_{q+1}, ..., \theta_r)\). Пусть \(\Theta_0 = \{\theta: (\theta_{q+1}, ..., \theta_r) = (\theta_{0, q+1}, ..., \theta_{0, r})\}\) Если \(H_0\) верна, то \(\lambda(X^n) \sim \chi^2_{r-q, \alpha}\), где \(r-q\) -размерность \(\Theta\) минус размерность \(\Theta_0\), \(\alpha\) - уровень значимости.