🟦Bootstrap#
Bootstrap - это метод подсчета стандартных ошибок и доверительных интервалов статистических функциоалов. Основан на моделировании процесса получения выборок из генеральной совокупности при помощи многократного случайного выбора с возвращением из исходной выборки.
Алгоритм:
Строим от 1000 до 10000 выборок (бутстрапированных) размером с изначальную выборку.
В каждой считаем интересующую нас статистику \(\hat{\theta}_i.\)
Строим распределение \((\hat{\theta}_1, \hat{\theta}_2, ..., \hat{\theta}_B)\), где \(B\) - количество бутстрапированных выборок.
Проверка гипотезы о равенстве средних.
Есть 2 выборки \(X_1, X_2, ..., X_n \sim F_X\) и \(Y_1, Y_2, ..., Y_n \sim F_Y\)
Гипотезы: \(H0: Е[X] = E[Y]\) \(H1: E[X] \neq E[Y]\)
Сгенерируем \(B\) пар подвыборок расзмером \(n\) из выборок \(X^n\) и \(Y^n\). Для каждой пары считаем разность выборочных средних и стром по этому множеству доверительный интервал. Если доверительный интервал не содержит 0, то, как правило, нулевая гипотеза отклоняется.
Подобным образом можно сравнивать любые статистики, от средних до квантилей.
🔹Способы построения доверительных интервалов Bootstrap#
Пусть с помощью Bootstrap получили \(B\) оценок \(\hat{\theta}_1, \hat{\theta}_2, ..., \hat{\theta}_B\)
Нормальный интервал
Предположим, что полученное множество статистик, посчитанных на бутстраппированных данных, имеет нормальное распределение, тогда доверительный интвервал будет иметь вид: \((\hat{\theta} - C_1 \cdot \hat{se}_{boot}, \hat{\theta} + C_2 \cdot \hat{se}_{boot})\), где \(\hat{\theta}=\overline{X}^n - \overline{Y}^n\) - разность выборочных средних, \(\hat{se}_{boot} = \sqrt{\frac{1}{B}\sum_{i=1}^B \left(\hat{\theta}_i - \overline{\theta}_B\right)^2}\) - оценка стандартной ошибки на основе bootstrap, \(C_1 = q_{N(0, 1)}\left( \frac{\alpha}{2}\right)\), \(C_2 = q_{N(0, 1)}\left( 1-\frac{\alpha}{2}\right)\).
Интервал на основе процентилей
Может быть так, что распределение оценок имеет не нормальное распределение. В таком случае можно использовать следующий доверительный интервал \((\theta^*_{\alpha/2}, \theta^*_{1 - \alpha/2})\), где \(\theta^*_\alpha\) - \(\alpha\)-квантиль, посчитанный по множеству \((\theta_{n, 1}, \theta_{n, 2}, ...,\theta_{n, B})\).
Центральный интервал
Пусть \(\theta = T(F)\) и \(\hat{\theta}_n = T(\hat{F_n})\).
Введем \(R_n = \hat{\theta}_n - \theta\) (смещение выборочной оценки относительно параметра) с распределеним \(H(r) = P_F(R_n \leq r)\). Определим доверительный интервал \((a, b) = \left(\hat{\theta}_n - H^{-1}\left(1 - \frac{\alpha}{2}\right),\,\, \hat{\theta}_n - H^{-1}\left(\frac{\alpha}{2}\right)\right)\)
Мы хотим, чтобы интервал покрывал \(\theta\) с вероятностью \(1 - \alpha\).
Это эквивалентно условию для распределения ошибки \(R_n = \hat{\theta}_n - \theta\) (тупо подставили \(R_n\) вместо \(\theta\) в формулу выше), т.е.
Но мы не знаем \(H(r)\), поэтому попробуем оценить его с помощью бутстрапа:
где \(R^*_{n, i} = \hat{\theta}^*_{n, i} - \hat{\theta}_n\), где \(\hat{\theta}^*_{n, i}\) - оценка параметра по бутстраппированной выборкe, а \(\hat{\theta}_n\) - оценка параметра по исходной выборке.
Пусть \(r^*_\beta\) - \(\beta\) выборочная квантиль, посчитанная по выборке \((R^*_{n, 1}, R^*_{n, 1}, ..., R^*_{n, B})\), а \(\theta^*_\beta\) - \(\beta\) выборочная квантиль, посчитанная по выборке \((\hat{\theta}^*_{n, 1}, \hat{\theta}^*_{n, 1},...,\hat{\theta}^*_{n, B})\), тогда
Замечание
\(r^*_{\alpha/2} = \theta^*_{\alpha/2} - \hat{\theta}_n\) т.к. \(H^*(r) = P(R^*_n \leq r| X_1, X_2, ..., X_n)\). Тогда \(\beta\) - квантиль \(R^*_n\) (обозначим как \(r^*_\beta\)) определяется следующим образом:
По определению квантиля \(\theta^*_\beta = \hat{\theta}_n + r^*_\beta\), таким образом, \(r^*_\beta = \theta^*_{\beta} + \hat{\theta}_n\).
Код
Ошибки первого и второго рода#
Для проверки корректности работы статистических тестов на практике принято применять технологию AAB-тестирования. По возможности мы стараемся подобрать две выборки из контрольной группы и одну из пилотной. Если всё идет хорошо, то алгоритм должен заметить разницу между пилотной и контрольной выборками, но при этом не показать различия между двумя контрольными группами.
Вероятность ошибки первого рода — вероятность отвергнуть нулевую гипотезу при условии, что она верна. То есть вероятность обнаружить значимые различия между двумя контрольными группами. Ведь их не должно быть!
Вероятность ошибки второго рода — вероятность не отвергнуть нулевую гипотезу при условии, что верна альтернативная гипотеза. То есть вероятность не найти значимых различий между пилотной и контрольной группами. А мы очень хотим их найти!
Создадим вспомогательные функции для проведения экспериментов.
from collections import defaultdict
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import seaborn as sns
def check_ttest(a, b, alpha=0.05):
"""Тест Стьюдента. Возвращает 1, если отличия значимы."""
_, pvalue = stats.ttest_ind(a, b)
return int(pvalue < alpha)
def check_mannwhitneyu(a, b, alpha=0.05):
"""Тест Манн-Уитни. Возвращает 1, если отличия значимы."""
_, pvalue = stats.mannwhitneyu(a, b, alternative='two-sided')
return int(pvalue < alpha)
def check_bootstrap(a, b, func=np.mean, B=1000, alpha=0.05):
"""Бутстрап. Возвращает 1, если отличия значимы."""
a_bootstrap = np.random.choice(a, size=(len(a), B))
b_bootstrap = np.random.choice(b, size=(len(b), B))
list_diff = func(a_bootstrap, axis=0) - func(b_bootstrap, axis=0)
left_bound = np.quantile(list_diff, alpha / 2)
right_bound = np.quantile(list_diff, 1 - alpha / 2)
res = 1 if (left_bound > 0) or (right_bound < 0) else 0
return res
dict_tests = {
'ttest': check_ttest,
'mannwhitneyu': check_mannwhitneyu,
'bootstrap': check_bootstrap
}
def aab_samples_generator(dist_a, dist_b):
def _get_aab_sample(sample_size):
a_one = dist_a.rvs(size=sample_size)
a_two = dist_a.rvs(size=sample_size)
b = dist_b.rvs(size=sample_size)
return (a_one, a_two, b)
return _get_aab_sample
def run_experiment(sample_sizes, aab_sample_generator, N=1000):
first_type_errors = defaultdict(list)
second_type_errors = defaultdict(list)
for sample_size in sample_sizes:
aa_results = defaultdict(list)
ab_results = defaultdict(list)
for _ in range(N):
a_one, a_two, b = aab_sample_generator(sample_size)
for name, test in dict_tests.items():
aa_results[name].append(test(a_one, a_two))
ab_results[name].append(test(a_one, b))
for name in dict_tests:
first_type_errors[name].append(np.mean(aa_results[name]))
second_type_errors[name].append(1 - np.mean(ab_results[name]))
return sample_size, first_type_errors, second_type_errors
def plot_errors(x, data: dict, title='', xlabel=''):
for key, values in data.items():
plt.plot(x, values, label=key)
plt.legend()
plt.ylim([-0.05, 1.05])
plt.title(title)
plt.xlabel(xlabel)
plt.grid()
plt.show()
Сравнение двух смещенных нормальных распределений#
Посмотрим как справятся наши тесты с двумя смещенными на небольшую величину нормальными распределениями. Удастся ли нам различить их на заданном уровне значимости?
sample_sizes = np.logspace(2, 3, 10).astype(int)
generator = aab_samples_generator(
dist_a=stats.norm(loc=0, scale=1),
dist_b=stats.norm(loc=0.2, scale=1)
)
_, first_type_errors, second_type_errors = run_experiment(sample_sizes, generator)
plot_errors(sample_sizes, first_type_errors, 'first_type_errors', 'sample_size')
plot_errors(sample_sizes, second_type_errors, 'second_type_errors', 'sample_size')
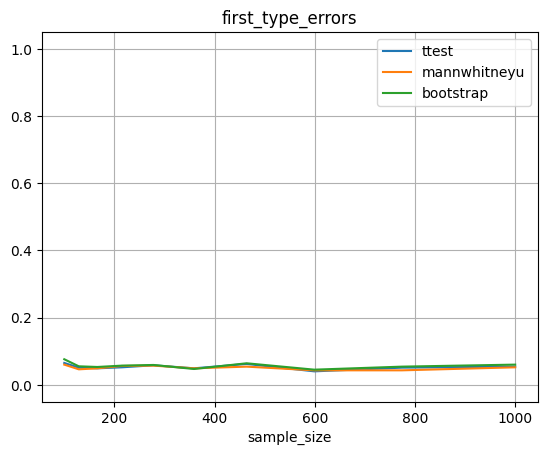
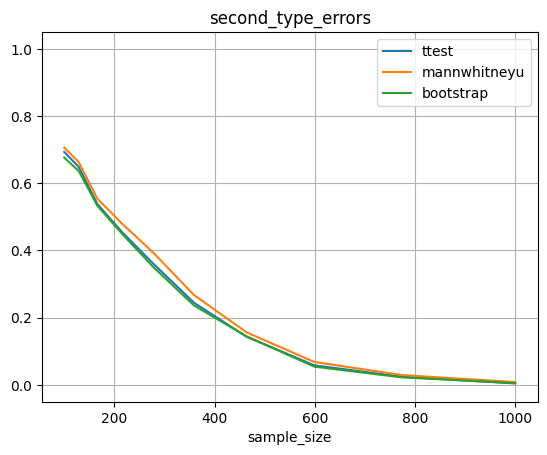
Ошибки первого типа держаться на уровне 0.05, а ошибки второго уровня уменьшаются при увеличении выборки. Результаты для теста Стьюдента и теста Манна-Уитни очень похожи, тест Стьюдента может едва выигрывает в точности.
Сравнение для не нормально-распределенных данных#
Проверим как будут вести себя тесты при генерации данных из экспоненциального распределения.
sample_sizes = np.logspace(2, 3, 10).astype(int)
generator = aab_samples_generator(
dist_a=stats.expon(loc=0, scale=1.0),
dist_b=stats.expon(loc=0, scale=1.2)
)
_, first_type_errors, second_type_errors = run_experiment(sample_sizes, generator)
plot_errors(sample_sizes, first_type_errors, 'first_type_errors', 'sample_size')
plot_errors(sample_sizes, second_type_errors, 'second_type_errors', 'sample_size')
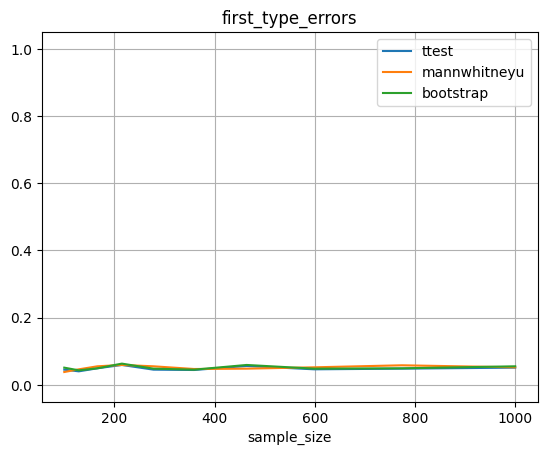
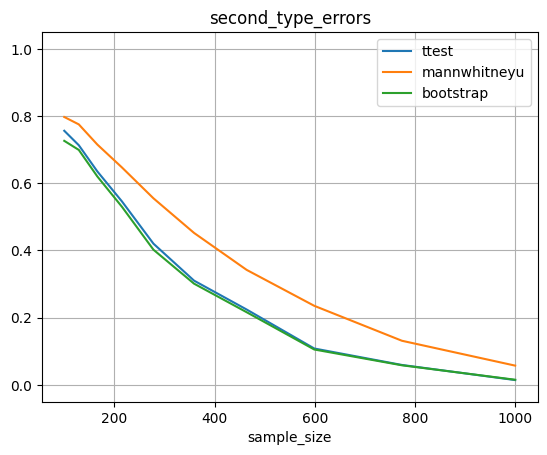
Тест Манна-Уитни в этой задаче дает больше ошибок.
Чувствительность к выбросам#
Проверим как ведут себя тесты при наличии выбросов в данных.
Зафиксируем размер выборки, будем заменять одно значений в одной выборке на сильно отличающееся от среднего.
N = 1000
outliers = np.arange(-150, 300 + 1, 15)
test_first_type_errors = defaultdict(list)
test_second_type_errors = defaultdict(list)
sample_size = 500
for outlier in outliers:
test_first_type_results = defaultdict(list)
test_second_type_results = defaultdict(list)
for _ in range(N):
a_one = np.random.normal(0, 1, sample_size)
a_one[0] = outlier
a_two = np.random.normal(0, 1, sample_size)
b = np.random.normal(0.2, 1, sample_size)
for test_name, test in dict_tests.items():
result_aa = test(a_one, a_two)
result_ab = test(a_one, b)
test_first_type_results[test_name].append(result_aa)
test_second_type_results[test_name].append(result_ab)
for test_name in dict_tests:
test_first_type_errors[test_name].append(np.mean(test_first_type_results[test_name]))
test_second_type_errors[test_name].append(1 - np.mean(test_second_type_results[test_name]))
plot_errors(outliers, test_first_type_errors, 'first_type_errors', 'outlier')
plot_errors(outliers, test_second_type_errors, 'second_type_errors', 'outlier')
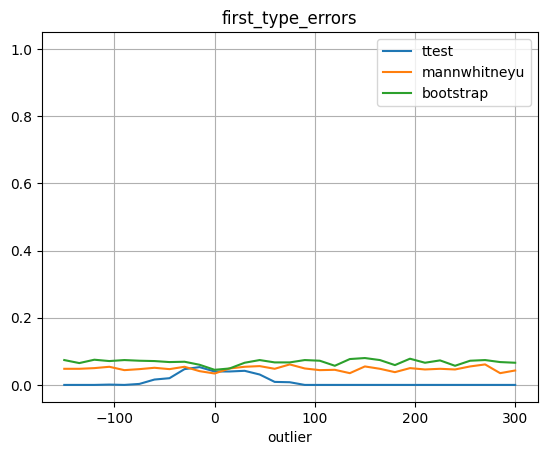
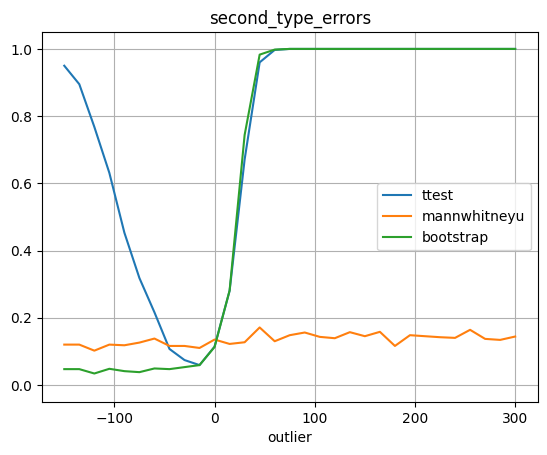
Видно, что при увеличении размера выброса, ошибка второго рода для теста Стьюдента сильно увеличивается, когда тест Манна-Уитни не обращает большого внимания на выброс. Связано это с тем, что тест Стьюдента - параметрический тест и отдельный выброс портит нам параметры. В то время как Манн-Уитни основан на рангах элементов. То есть один испорченный объект портит значения только в связанных с ним парах, но не затрагивает остальные. В этом смысле мы получаем большую устойчивость к редким большим выбросам. Этот выброс не так сильно меняет математическое ожидание, но очень сильно меняет диспресию, из-за чего t-тест стремится к 0 и мы не видим значимые различия, когда они на самом деле есть.(т.к. дисперсия стоит в знаменателе)
Представим, что в выборке теперь 5 выбросов.
N = 1000
outliers = np.arange(-150, 300 + 1, 15)
test_first_type_errors = defaultdict(list)
test_second_type_errors = defaultdict(list)
sample_size = 500
for outlier in outliers:
test_first_type_results = defaultdict(list)
test_second_type_results = defaultdict(list)
for _ in range(N):
a_one = np.random.normal(0, 1, sample_size)
a_one[:5] = outlier
a_two = np.random.normal(0, 1, sample_size)
b = np.random.normal(0.2, 1, sample_size)
for test_name, test in dict_tests.items():
result_aa = test(a_one, a_two)
result_ab = test(a_one, b)
test_first_type_results[test_name].append(result_aa)
test_second_type_results[test_name].append(result_ab)
for test_name in dict_tests:
test_first_type_errors[test_name].append(np.mean(test_first_type_results[test_name]))
test_second_type_errors[test_name].append(1 - np.mean(test_second_type_results[test_name]))
plot_errors(outliers, test_first_type_errors, 'first_type_errors', 'outlier')
plot_errors(outliers, test_second_type_errors, 'second_type_errors', 'outlier')
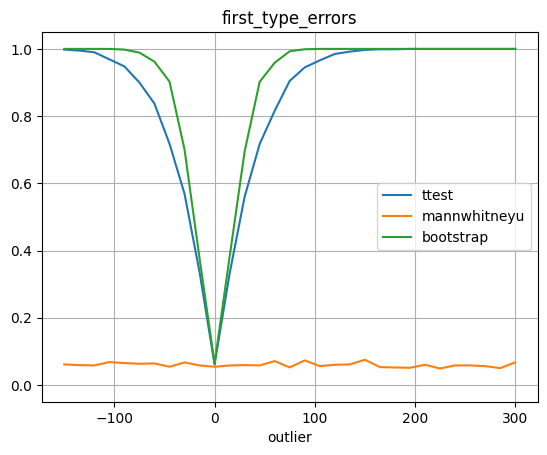
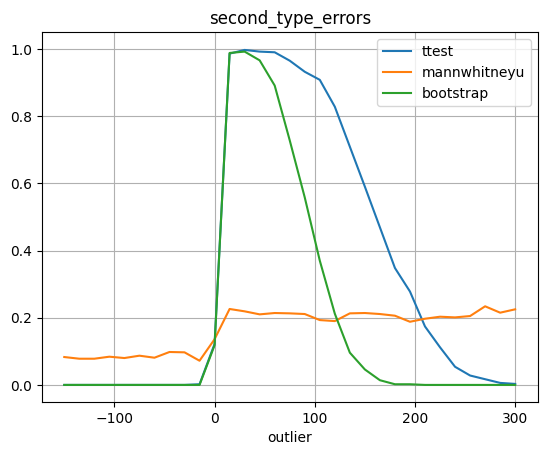
А тут выбросы уже сильно влияют на математическое ожидание, поэтому ошибка 1 рода выглядит так, как выглядит.
Бутстрап и доверительные интервалы#
Суть метода бутстрап состоит в том, чтобы по имеющейся выборке мы можем построить эмпирическое распределение. Это эмпирическое распределение будет апроксимировать исходное неизвестное нам распределение.
Для того, чтоб узнать значение произвольной статистики мы можем сгенерировать случайную выборку из распределения. Поскольку настоящее распределение нам неизвестно, то мы заменяем его апроксимацией — указанным ранее эмпирическим распределением. Напомним, что генерация выборки из эмпирического распределения эквивалентна выбору с возвращениями из породившей это эмпирическое распределение выборки. Такой выбор на практике удобно осуществлять с помощью функции numpy.random.choice:
random.choice(a, size=None, replace=True, p=None)
При этом мы можем указать размер выборки — произвольный кортеж натуральных чисел. Такой способ гораздо эффективнее, чем последовательно генерировать несколько выборок.
Каждая из порожденных выборок дает нам точечную оценку для интересующей нас статистики. В целом же многократно сгенерированные выборки дают нам возможность построить распределение интересующей статистики.
Нахождение распределение статистики с помощью бутстрапа#
Задача. Сгенерируем выборку из экспоненциального распределения. На её основе можно сформировать множество бутстрепных подвыборок. Наша задача посчитать точечную оценку для коэффициента ассиметрии, а так же на основе бутстрепных оценок построить распределение для этой статистики. И указать доверительный интервал. Сравнить всё это с известным теоретическим значением коэффициента ассиметрии для экспоненциального распределения.
N = 100
distribution = stats.expon(loc=0, scale=1)
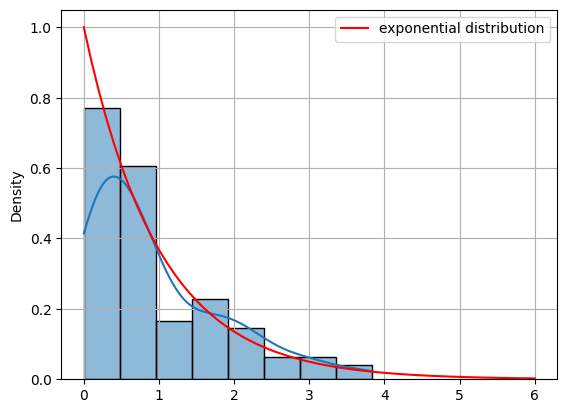
X = distribution.rvs(size=N, random_state=23)
x = np.linspace(0, 6, 61)
pdf = distribution.pdf(x)
sns.histplot(data=X, kde=True, stat='density')
plt.plot(x, pdf, label='exponential distribution', c='r')
plt.legend()
plt.grid()
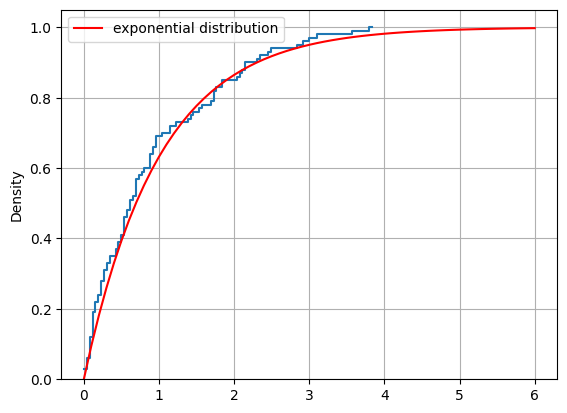
cdf = distribution.cdf(x)
sns.histplot(
data=X, cumulative=True, stat='density',
fill=False, element='step', bins=100)
plt.plot(x, cdf, label='exponential distribution', c='r')
plt.legend()
plt.grid()
Точечная оценка статистики#
Мы можем для нашей выборки получить точечную оценку коэффициента ассиметрии. Напомним, что вычисляется он как
$\(
\kappa=\frac{\mathbb{E}(X-\mu)^3}{\sigma^3}
\)\(
\)\(
\hat{\kappa}=\frac{n^{-1}\sum_i(X_i - \hat{\mu})^3}{\left(n^{-1}\sum_i(X_i - \hat{\mu})^2 \right)^{3/2}}
\)$
Для практического вычисления можно воспользоваться функцией scipy.stats.skew.
Так мы можем посчитать точечную оценку для нашей выборки и сравнить с известным значением для распределения. Кстати, если оно не известно, то его можно запросить.
sample_skewness = stats.skew(X)
distribution_skewness = distribution.stats(moments='s')
print(f'Коэффициент асимметрии распределения : {distribution_skewness}')
print(f'Коэффициент асимметрии выборки : {sample_skewness}')
Коэффициент асимметрии распределения : 2.0
Коэффициент асимметрии выборки : 1.2274496724312205
Процедура бутстрап и построение доверительных интервалов#
С помощью бутстрепа мы можем из имеющейся выборки сгенерировать множество подвыборок. Для каждой из этих подвыборок можно построить точечную оценку и тем самым получить распределение бутстрепных точечных оценок для интересующей нас статистики.
Для таких распределений мы можем построить доверительные интервалы. Например, доверительный интервал на основе процентилей.
B = 10000
real_mean_f = distribution.stats(moments='s')
list_points = []
count_x = np.arange(20, 101, 5)
for size in count_x:
sub_X = X[:size]
bootstrap_X = np.random.choice(sub_X, size=(size, B))
bootstrap_skewness = stats.skew(bootstrap_X, axis=0)
list_points.append(bootstrap_skewness)
alpha = 0.05
array_points = np.array(list_points)
bounds = np.quantile(array_points, [alpha/2, 1-alpha/2], axis=1)
means = np.mean(array_points, axis=1)
plt.fill_between(count_x, bounds[0], bounds[1], alpha=0.1, label='95% CI bootstrap')
plt.plot(count_x, means, label='mean bootstrap')
plt.plot(count_x, np.full(len(count_x), distribution_skewness), '--k', label='distribution skewness')
plt.plot(count_x, [stats.skew(X[:size]) for size in count_x], ':r', label='point estimation')
plt.legend()
plt.xlabel('size')
plt.ylabel('skewness')
plt.grid()
plt.show()
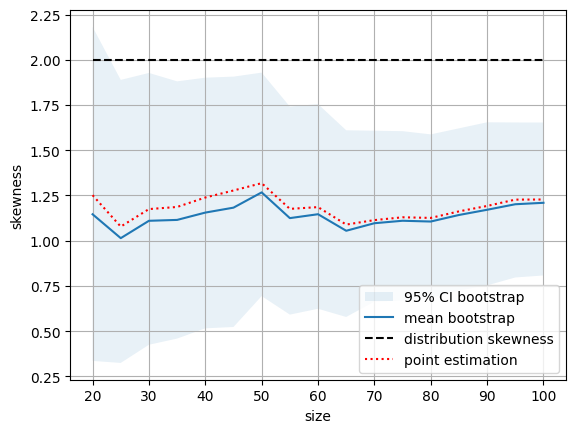
Важно заметить, что при всей мощи бутстрепа он не может преодолеть недостатки конкретной выборки. Если сгенерированная нами выборка не отражает определенных свойств исходного распределения, то бутстрепу дополнительную информацию брать просто неоткуда. Мы это видим и на графиках. В частности даже доверительные интервалы могут не покрыть истинного значения.
Ограничение применимости бутстрепа#
Мы видели в предыдущем пункте, что построенный с помощью бутстрепа доверительный интервал вообще может не покрыть истинные значения. Давайте разберемся в связи с чем это происходит.
Поскольку у нас есть доступ к реальному распределению, то мы можем повторить процедуру генерирования выборок и построить распределение точечных оценок в зависимости от размера выборки. Не перепутайте эту процедуру с бутстреп!
for sample_size in [20, 50, 100, 250, 500, 5000]:
X = distribution.rvs(size=(sample_size, 10000))
skewness = stats.skew(X, axis=0)
sns.histplot(
skewness, stat='density',
kde=True, fill=False,
element='step', label=f'size = {sample_size}')
plt.xlim(0, 4)
plt.legend()
<matplotlib.legend.Legend at 0x1f0c2752750>
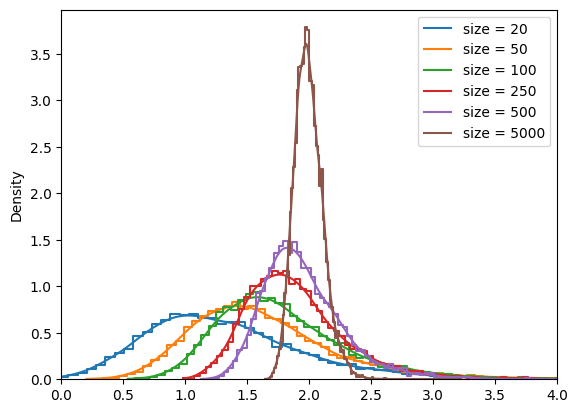
Успех мы можем получить только в той степени, в какой исходная выборка отражает структуру распределения. То есть необходимо помнить о уровне репрезентативности исходной выборки. Так можно посмотреть на доверительные интервалы для этих данных.
Почему же бутстреп популярен?#
Всё очень просто. При всех ограничениях бутстрепа у нас часто нет возможности получить дополнительные данные. Т.к. получение данных очень дорогое удовольствие.
Поэтому бутстреп часто безальтернативен. Им стоит пользоваться. Но необходимо помнить о существующих ограничениях.