🟦Композиции деревьев (Ансамбли)#
С помощью бутстрапа из обучающей геренируем выборки \(X_1, X_2, ..., X_n\). Обучаем \(n\) моделей: \(b_1(X_1), b_2(X_2), ..., b_n(X_n)\).
Ошибку для каждого алгоритма в случае MSE можно записать следующим образом:
\(\varepsilon^2_j = (b_j(x) - y(x))^2\)
\(\mathbb{E}_x{[b_j(x) - y(x)]^2} = \mathbb{E}_x\varepsilon^2_j\) - насколько каждая модель в среднем ошибается (вектор средних).
Обозначим за \(E_1\) среднеожидаемую ошибку всех моделей.
\(E_1 = \frac{1}{N} \sum_{i=1}^n \mathbb{E}_x \varepsilon_i^2 \,\,\,\,\,\,\,\,(*)\)
Построим бэггинг алгорим \(a(x) = \frac{1}{n} \sum_{i=1}^n b_i(x)\) и замерим ее ожидаемую ошибку \(\mathbb{E}_n\).
\( \mathbb{E}_n = \mathbb{E}_x\left[\frac{1}{n} \sum_{j=1}^nb_j(x) - y(x)\right]^2 = \mathbb{E}_x\left[\frac{1}{n} \sum_{j=1}^nb_j(x) - \frac{1}{n}\sum_{j=1}^n y(x)\right]^2 = \)
\( = \mathbb{E}_x\left[\frac{1}{n} \sum_{j=1}^n \varepsilon_j(x)\right]^2 = \frac{1}{N^2} \mathbb{E}_x\left[ \sum_{j=1}^n \varepsilon_j^2(x) + \sum_{i \neq j} \varepsilon_j \varepsilon_i\right] \)
Т.о. в случае, если ошибки не скоррелированы, т.е. \(\mathbb{E}\varepsilon_i\varepsilon_j = 0 (i \neq j)\), то получим
\( \frac{1}{n}\frac{1}{n}\sum_{j=1}^n \mathbb{E}_x\varepsilon_j^2(x) = \frac{1}{n} \mathbb{E}_1 \)
Т.е. усреднение \(N\) моделей уменьшает матожидание ошибки в \(N\) раз, в случае, сли модели нескоррелированы. Но в реальности так не бывает.
🟦Random Forest#
Обучаем глубокие деревья (например с min_samples_leaf=3);
Обучаемся на bootstrap выборках;
В каждой вершине \([x_j \geq t]\) выбирается из случайного подмножества признаков размера \(k\). Подмножества свои в каждой вершине.
Как выбрать k? Ну вообще-то уже за нас все посчитали и
для классификации: \(k = \lfloor \sqrt{d} \rfloor\)
для регрессии: \(k = \lfloor \frac{d}{3} \rfloor\)
Финальная модель:
классификация: \(\argmax_{y \in \mathbb{Y}} \sum_{j=1}^n \left[b_n(x) = y\right]\)
регрессия: \(\frac{1}{n} \sum_{j=1}^n b_n(x)\)
Важное свойство: при увеличении количества деревьев модель не начинает переобучаться.
🟦Градиентный бустинг#
Основная идея: каждая следующая модель корректирует ошибки предыдущей.
Бустинг для регресии#
\(\frac{1}{l} \sum_{i=1}^l (a(x_i) - y_i)^2 \to \min\)
\(a_N(x) = \sum_{n=1}^N \gamma_n b_n(x)\), где \(\gamma_n \in R\)
\(b_1(x) = \frac{1}{l} \sum_{i=1}^l (b_1(x_i) - y_i)^2 \to \min_{b_1}\,\,\,\,\,\,\, \gamma_1 = 1\)
Я хочу, чтобы \(b_1(x_i) + b_2(x_i) = y_i\), тогда \(b_2(x_i) = y_i - b_1(x_i) = s_i\)
Тогда 2-я модель будет выглядеть следующим образом:
\(\frac{1}{l} \sum_{i=1}^l (b_2(x_i) - s_i)^2 \to \min_{b_2}\)
Отсюда \(\gamma_2 = \argmin_{\gamma \in R} \frac{1}{l} \sum_{i=1}^l \left(b_1(x) + \gamma_2b_2(x) - y_i\right)^2\)
Дальше тоже самое:
\(b_3(x): s_i^{(2)} = y_i - b_1(x_i) - b_2(x_i)\)
\(\frac{1}{l} \sum_{i=1}^l (b_3(x_i) - s_i)^2 \to \min_{b_3}\) и т.д.
Общий случай#
\(L(y, z)\) - Дифференцируемая функция потерь.
\(a_N(x) = \sum_{i=1}^N \gamma_nb_n(x)\)
\(b_1(x)\) обучаем как умеем, а гаммы будет в будущем лучше отбирать.
\(\frac{1}{l} \sum_{i=1}^l L (y_i, b_1(x_i)) \to \min\)
Далее мы ищем \(b_N(x)\) при условии, что \(b_1(x), b_2(x), ..., b_{N-1}(x)\) зафиксированы:
\(\frac{1}{l} \sum_{i=1}^l L(y_i, a_{N-1}(x_i) + b_N(x_i)) \to \min_{b_N}\)
Возьмем функцию потерь в точке текущего прогноза компизиции, посчитаем производную и отредактируем ошибку на текущем прогнозе.
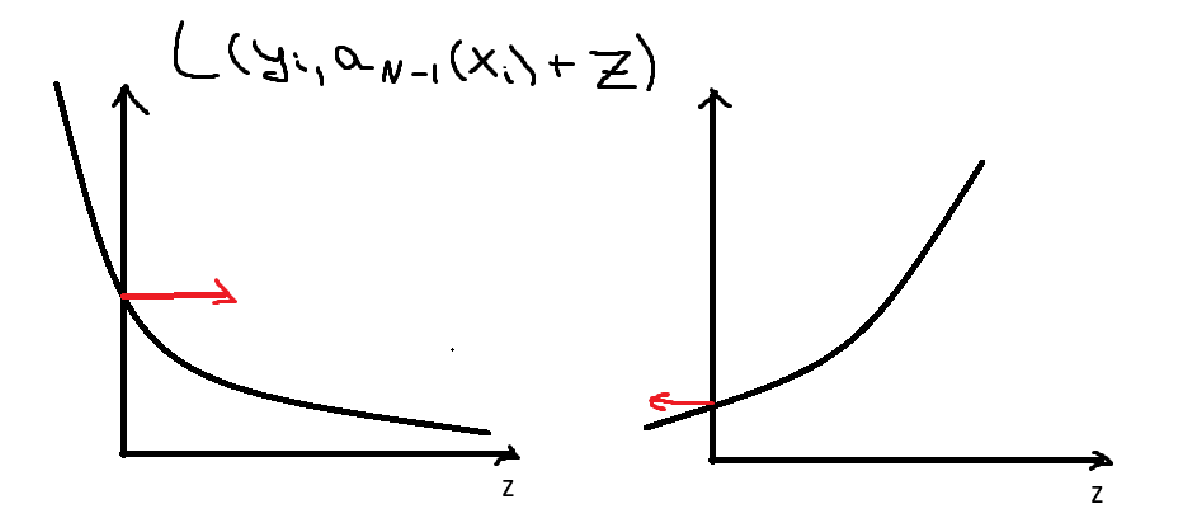
\(s_i = \frac{\partial}{\partial z} L(y_i, z_i)\Big|_{z=a_{N-1}(x_i)}\)
\(\left[ \begin{gathered} \frac{1}{l} \sum_{j=1}^l (b_N(x_i) - s_i)^2 \to \min_{b_N} \\ s_i = \frac{\partial}{\partial z} L(y_i, z_i)\Big|_{z=a_{N-1}(x_i)} \\ a_N = a_{N-1}(x) + b_N(x) \end{gathered} \right.\)
Тут градиент берется просто по функции потерь, а не по весам модели, чтобы просто знать, куда идти на определенном объекте. Тут градиентный спуск в пространстве объектов.
Базовые модли в бустинге должны быть простыми.
бэггинг |
бустинг |
|
|---|---|---|
Смещение |
↓ |
↓ |
Разброс |
- |
↑ |
Градиентный бустинг над деревьями#
\(b_n(x) = \sum_{j=1}^{J_n} b_{nj} [x\in R_{nj}]\) - связь деревьев с линейными моделями.
\(a_N(x) = a_{N-1}(x) + \sum_{j=1}^{J_N} b_{Nj} [x\in R_{Nj}]\)
Идея: подберем \(b_{Nj}\), чтобы были оптимальные с точки зрения \(L(y, z)\).
Задача разбивается на \(J_N\) подзадач вида:
\(\sum_{(x_i, y_i) \in R_{Nj}} L(y_i, a_{N-1}(x_i) + \gamma) \to \min_{\gamma \in R}\)
По сути в каждом листе переподбираем прогнозы дерева.
Бустинг второго порядка#
Вернемся к постановке задачи
Разложим в ряд Тейлора по 2-му аргументу с центром в \(a_{N-1}(x_i)\) до 2 члена, тогда
Перепишем, отбросив лишнее:
Ну и что это? Чтобы дать ответ на этот вопрос, посчитаем следующую штуку:
Таким образом, то, что мы вывели раннее - это по сути минимизация MSE, но с одним отличием \(\boxed{?}\).
Регуляризация#
Что можно сделать, чтобы ослабить переобучение базовых моделей?
\(b(x) = \sum_{j=1}^{J} b_j[x \in Rj]\)
Показатели сложности дерева:
Большое \(J\)(кол-во листьев);
\(||b|| = \sum_{j=1}^J b_j^2\) - чем больше, тем выше шансы на сильное уменьшение композиции.
Добавим регуляризаторы в функционал:
Пусть структура дерева уже фиксирована. Вспомним, что деревья выдают один и тотже прогноз для объектов из одного листа.
квадратный многочлен от \(b_j\), можем найти минимум:
\(b_j^* = \frac{S_j}{H_j} + \lambda\)
Подставим и получим:
Функционал ошибки для дерева при оптимальных прогнозах в листьях
Будем использовать \(H(b)\) для выбора предиката
\(Q(R, j, t) = H(R) - H(R_l) - H(R_r)\)
где
R - текущая вершина
j - признак, по которому разбиваем
Т.о. учли вторые производные, добавили регуляризацию, придумали критерий хаотичности напрямую зависящий от ф.п.
Все это называется XGboost.
Оптимизируем:
Критерий информативности:
Оптимальные значения в листьях